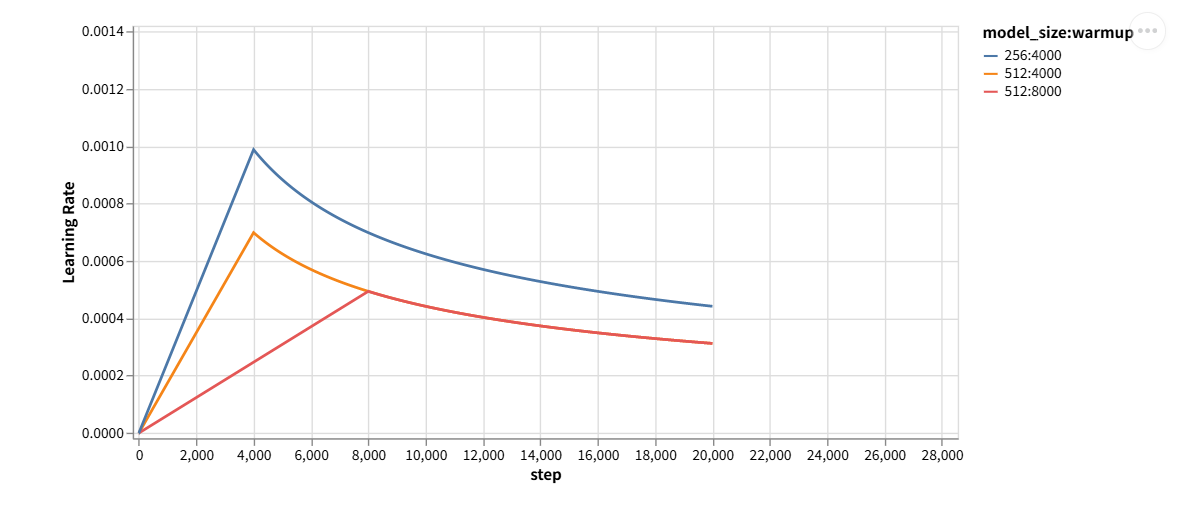
前言 请打开日间模式进行阅读 本来是想学习RoPE(旋转位置编码),所以回去从头从最开始的三角函数式位置编码开始看,发现自己当时学的还是浅了。在此总结一下。 注:本文涵盖不了所有位置编码,只挑主流的去学习。具体就是由绝对位置编码到相对位置编码再到RoPE 三角…
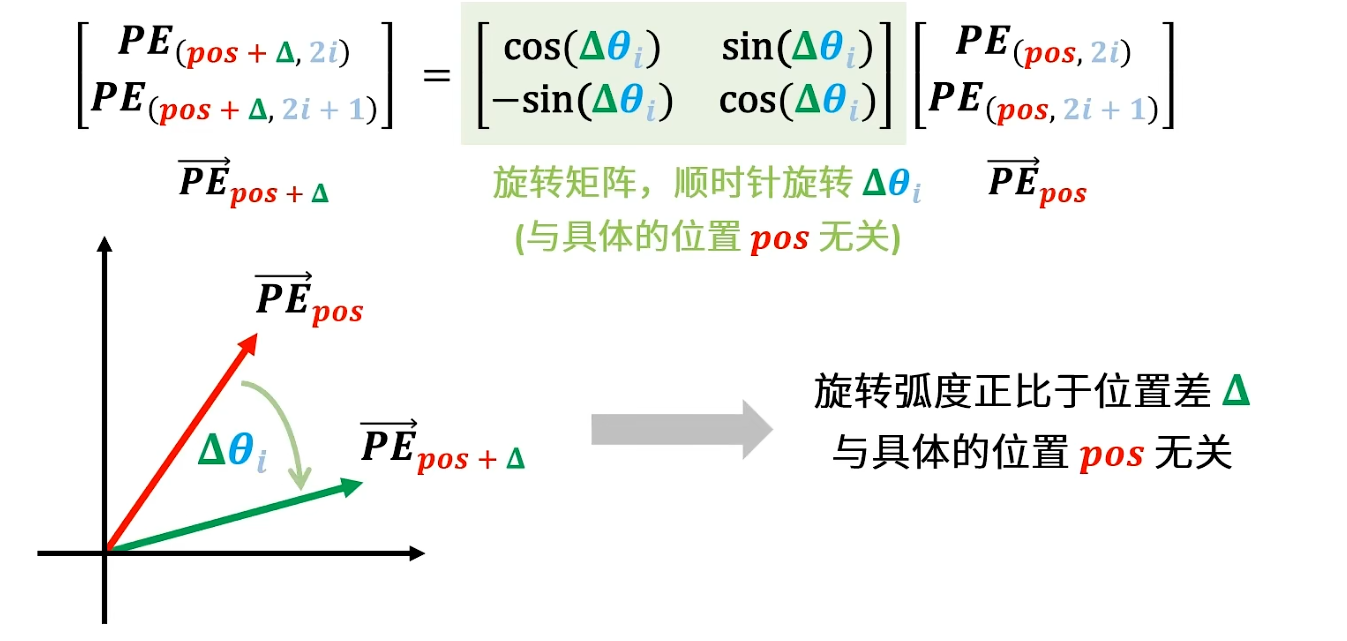
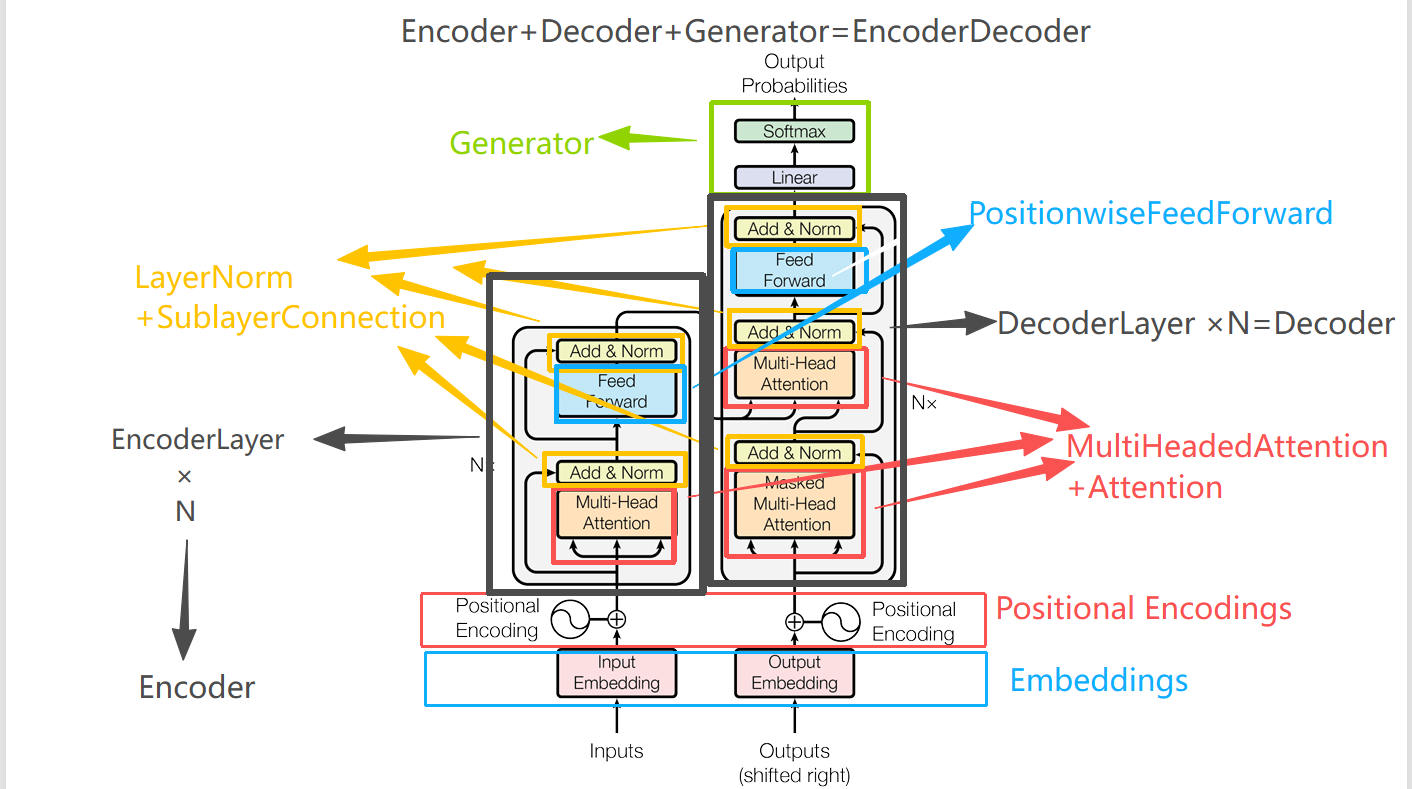
由Sinusoidal位置编码到RoPE

总所周知用nn.CrossEntropyLoss()算损失的时候需要将input_data和label展开对齐,也就是必须符合:(N,C)和(N)的格式,而在NER任务中最后往往输出的是:(batch_size,seq_len,class_num) 和(batch_size,seqlen),所以需要这两个view一下。我的代码是:
outputs = model(input_ids=input_ids)
ouputs=outputs.view(-1, num_classes) # (batch_size*seq_length, num_classes)
labels = labels.view(-1) # (batch_size*seq_length)
#print(outputs.shape, labels.shape, labels.dtype)
loss = criterion(outputs, labels)根本看不出有什么不对劲。 但是debug总是显示这里维度不匹配,问了好几遍GPT,他也没看出来,直到一遍遍排查,我把GPT说的所有可能的错误都说了,又发给他看。

我噗呲一下笑出来—————气笑了。 人在无语的时候真的想笑,尤其搭配上GPT这个语气,他真的好像人一样