前言:PEFT的诞生 传统的预训练-下游任务微调的范式,是对预训练模型所有参数进行微调,即全量微调。之前基于Bert、GPT1的下游微调任务都是这么干的。因为当时的预训练模型参数量比较少,所以速度并没有那么慢。…

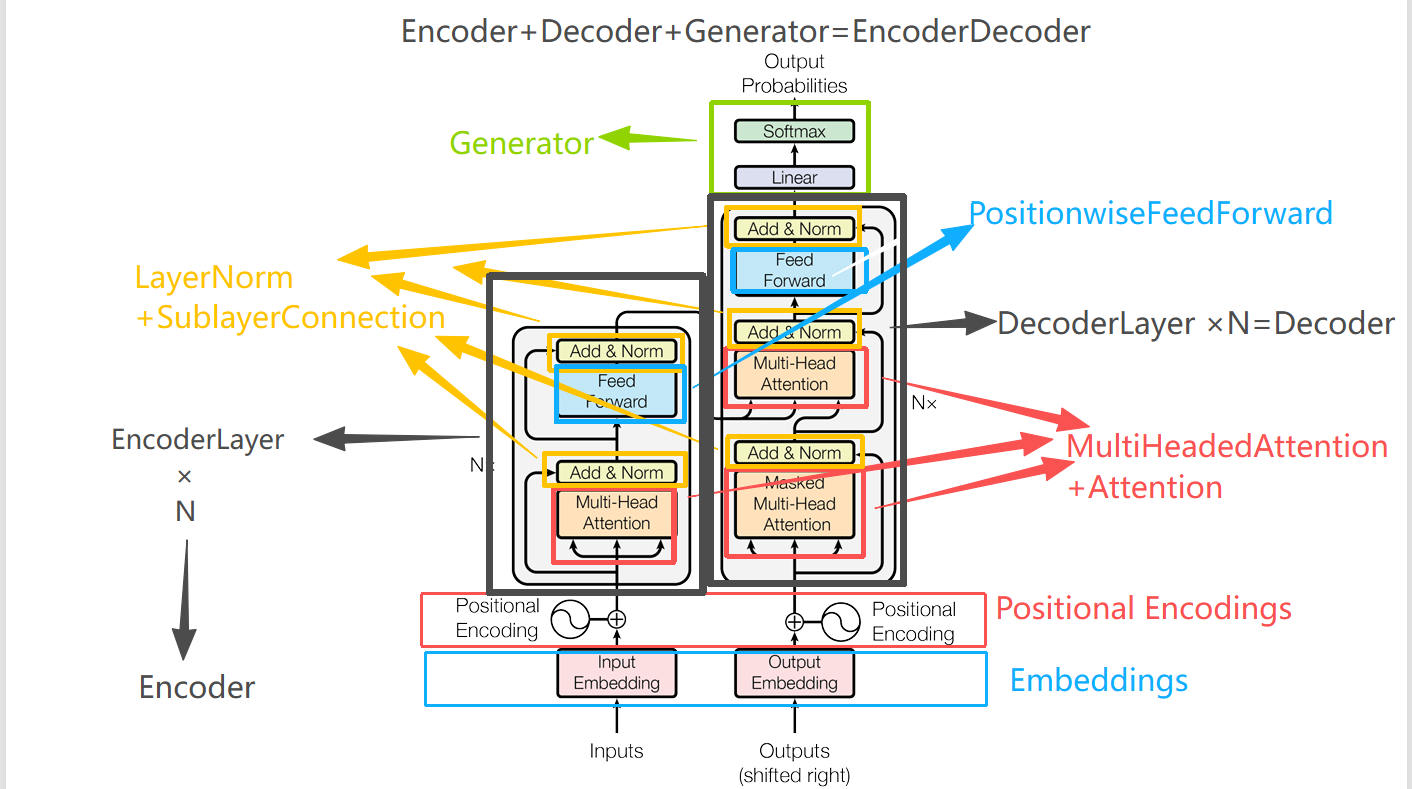
LoRA小结
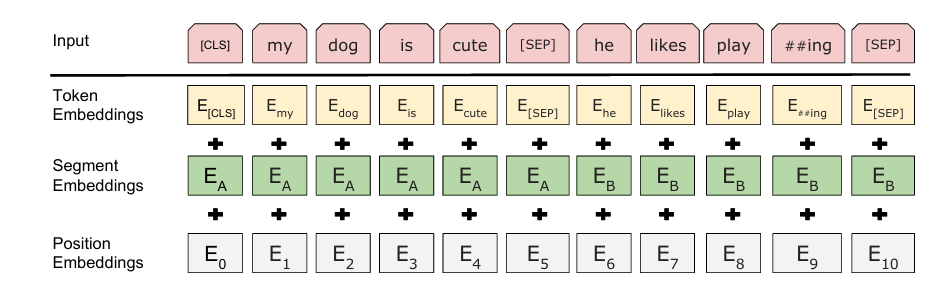
总所周知用nn.CrossEntropyLoss()算损失的时候需要将input_data和label展开对齐,也就是必须符合:(N,C)和(N)的格式,而在NER任务中最后往往输出的是:(batch_size,seq_len,class_num) 和(batch_size,seqlen),所以需要这两个view一下。我的代码是:
outputs = model(input_ids=input_ids)
ouputs=outputs.view(-1, num_classes) # (batch_size*seq_length, num_classes)
labels = labels.view(-1) # (batch_size*seq_length)
#print(outputs.shape, labels.shape, labels.dtype)
loss = criterion(outputs, labels)根本看不出有什么不对劲。 但是debug总是显示这里维度不匹配,问了好几遍GPT,他也没看出来,直到一遍遍排查,我把GPT说的所有可能的错误都说了,又发给他看。

我噗呲一下笑出来—————气笑了。 人在无语的时候真的想笑,尤其搭配上GPT这个语气,他真的好像人一样


我的博客只有图片挂了CDN,我这小破博客的访问量,一个月也就花个几毛钱,我也一直一块一块的续,直到前几天,我刚充了一块钱, 过了一天就欠费了。。。本来早上都不想来工位的,奈何电脑在工位,我还跑到工位看了半天。

四张图片刷了我8个G,一张图片的大小也就是几MB,
而且还不是来自同一个IP。。。
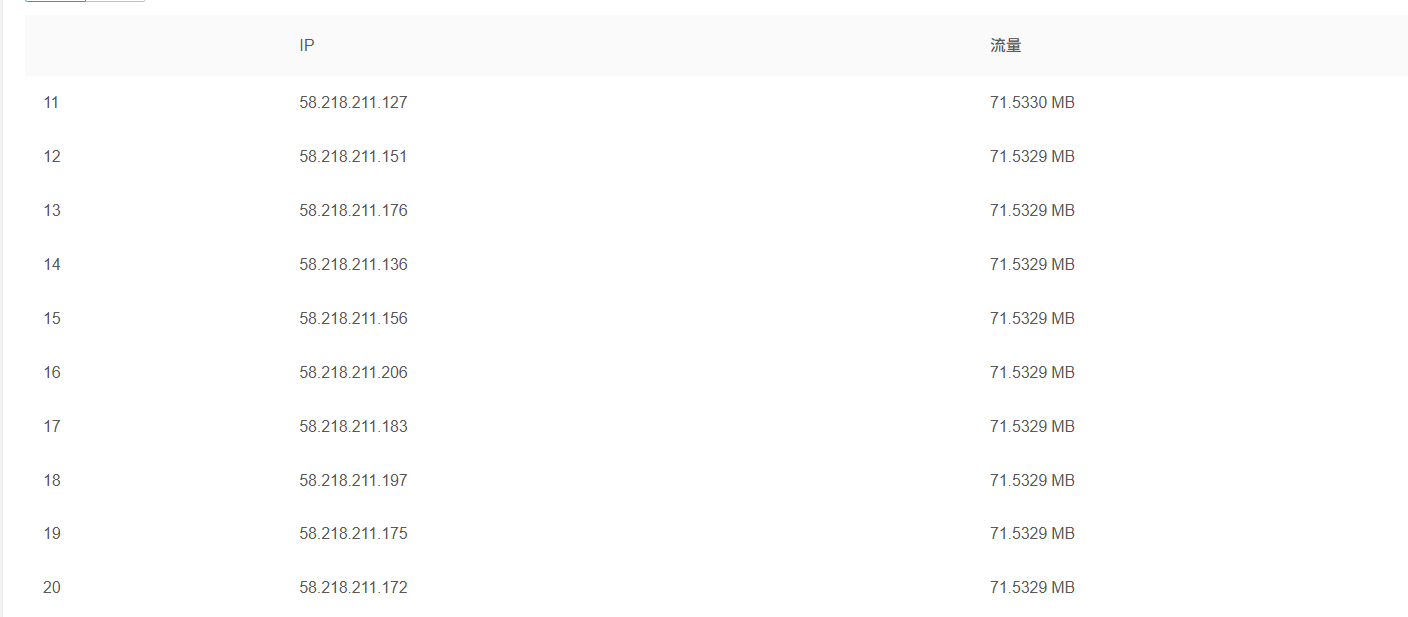
我这小破博客也没个什么,纯个人维护,别盯着我整了。。。