前言
学习解码器与编码器架构以及注意力机制是为了后边更好的学习Transformer架构。本文为作者学习encoder-decoder架构的学习笔记。
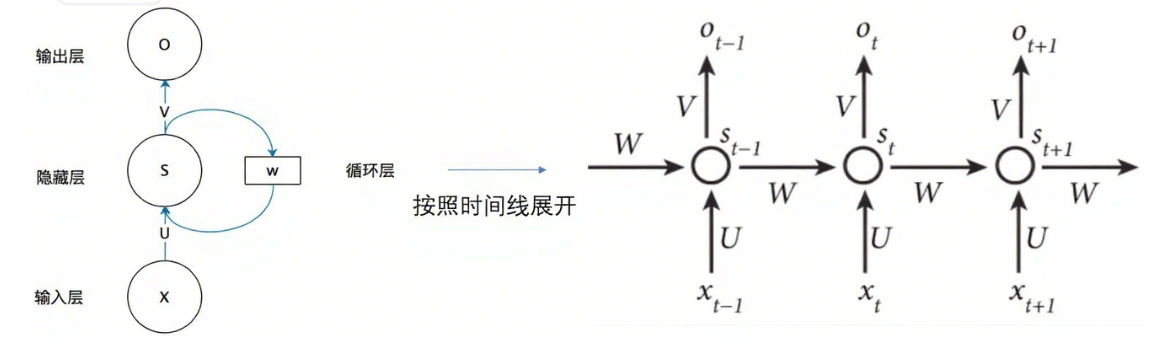
encoder-decoder架构
诞生背景
encoder-decoder架构是为了解决一类任务的:Seq2Seq模型,即序列到序列模型,虽然这里叫模型,但它本质上是一种任务,就和文本分类任务,序列标注等任务一样,他的需求是将输入的序列转换成一个输出序列。
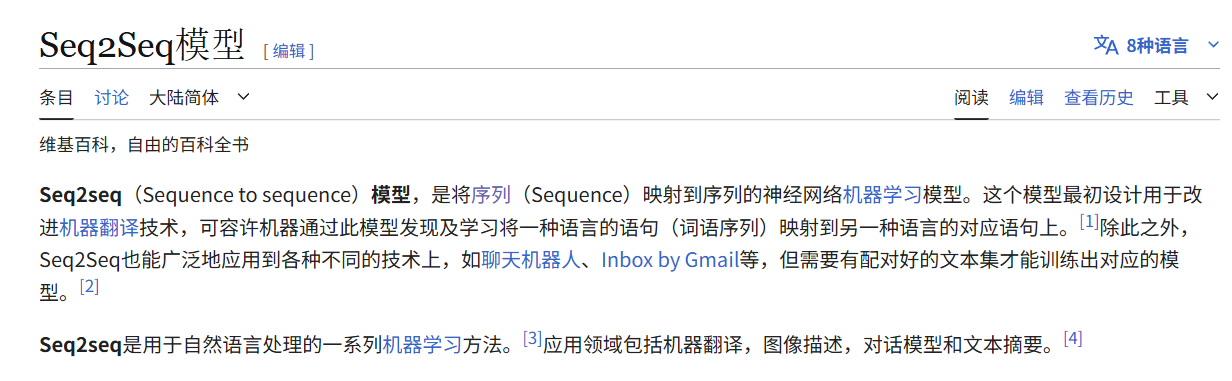
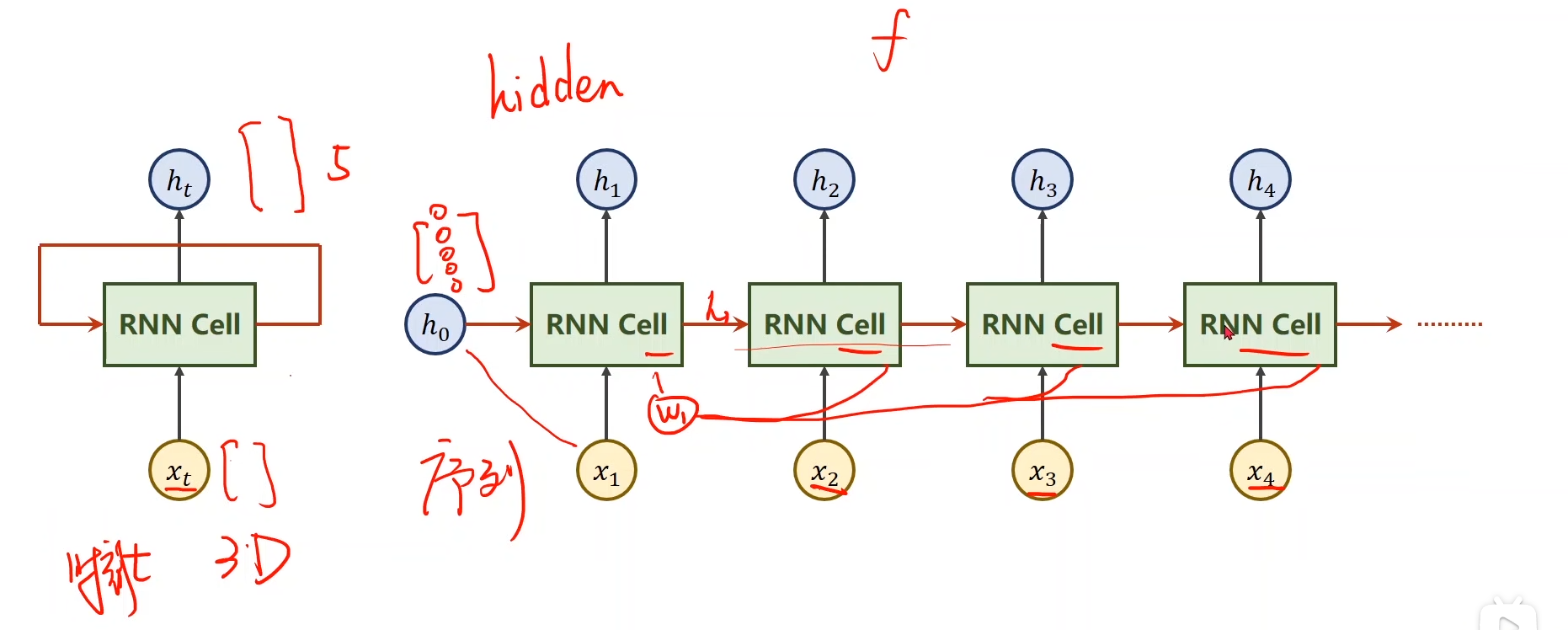
传统的RNN以及其改良的网络(LSTM、GRU)可以在每一时刻生成一个输出,而每一个时刻对应一个输入。
当处理Seq2Seq问题时,只能生成与输入序列相同长度的输出,或者少输出几个,也只能少于输入序列。
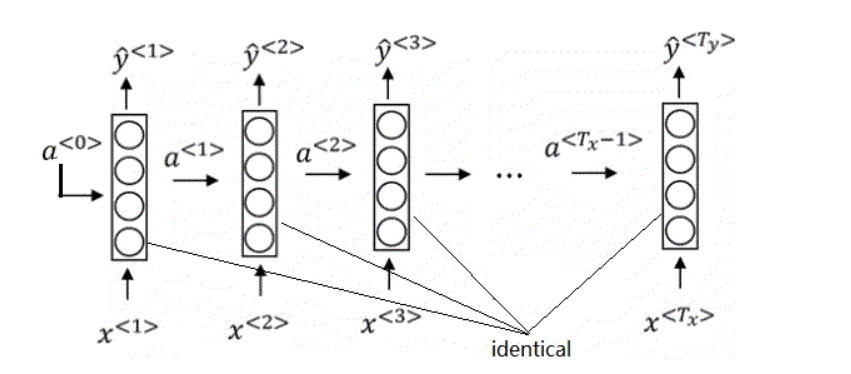
但是在Seq2Seq模型中,很多时候输入序列与输出序列的长度是不一样的。例如在翻译问题中,我们的输出序列很有可能比输入序列长。为了解决这类任务,encoder-decoder架构就诞生了。
架构介绍
本人认为这篇论文中的图片更通俗易懂。这篇论文就是将最开始的提出encoder-decoder架构论文中使用的RNN换成了LSTM。
Sequence to Sequence Learning with Neural Networks(https://arxiv.org/pdf/1409.3215)

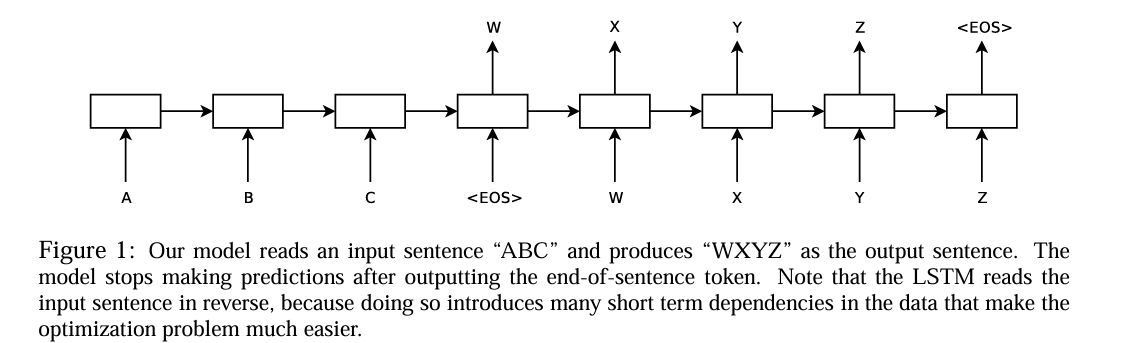
idea首先利用一个LSTM来去读取输入序列,每一个时间读取一个时间步,来获得维持一个大的,固定维度的向量表示,然后接着用另一个LSTM从这个向量表示中提取输出序列。第二个 LSTM 本质上是一个循环神经网络语言模型 ,除此之外它受输入序列影响(这里意思是他和传统的RNN有所不同的是,传统RNN输入的h0可能什么也没有,但是他输入的h0是经过了解码器加工后的向量。) 其他的我就先不翻译了。看完这句话,再结合图片,我们已经懂了这个架构的大概样子。读取序列的这个LSTM就是解码器,他相较于传统的LSTM,他不在每一个时间输出一个token,只是一个劲的向下传递,最终将所有的输入序列通过LSTM凝聚到一个输出向量中。encoder干的事情就是这个。之后将这个向量作为原始的隐藏层输入到另一个LSTM中,并且每一个时刻的输出也是下一个时刻的输入,这样,我们就可以一个接着一个的输出,完成Seq2Seq任务了。
这里我在学习的时候有一个问题:如何保证解码器不会无限的输出下去。这就用到了最开始学NLP基础知识用到的知识点:EOS(End of Sequence)标记

当模型预测到EOS标记时,便会停止预测
训练流程
整个架构实际上是端到端的,看起来是分了两个部分,编码器和解码器,但他们并不是说两个部分分开训练什么的,他们总体上是端到端训练的,前向传播先从编码器传播到解码器,之后输出,然后输出与实际样本目标进行比对,然后计算损失,反向传播,先传播到解码器部分,之后再穿回编码器部分,进行参数更新。
就像GoogLeNet一样,GoogLeNet有一个inception模块,该模块单独写一个类,之后在主网络中对此模块进行复用。而我们的encoder-decoder架构就是会单独写两个模块,分别是encoder和decoder,代码中就对应两个类。encoder类和decoder类,之后在主网络中,将这两个类拼接在一起,进行训练。就像搭积木一样。
如下图所示
src_tensor --> Encoder --> hidden/cell --> Decoder --> output logits --> Loss
^ |
|---------------------------------------------------------|
反向传播: loss 对 decoder -> encoder 端到端
代码实现
这里主要是一个很小很小的demo,来帮助理解,用的数据也是自己造的傻瓜式数据:
data = [
("你好", "hello"),
("谢谢", "thank you"),
("早上好", "good morning"),
("晚安", "good night"),
("再见", "goodbye"),
("我爱你", "i love you"),
("你好吗", "how are you"),
("我很好", "i am fine"),
]
数据预处理
这里是我还没涉及到的地方,借助GPT,先浅学习了一波,用了一些简单的数据预处理方法,后续再详细学这片。
主要流程为:
文字 → 索引序列 → embedding向量 →Encoder → hidden/cell → Decoder → output logits
1. 文字到索引:
这里我们需要先构建词表,因为,将每一个字,每一个词都分开,这里就先简单粗暴的分开,即:中文每一个字都是一个词,英文每一个单词就是一个词。这样每一个词代表一个token,同时我们需要在词表中加入"<PAD>", "<SOS>", "<EOS>"这三个特殊符号(padding,start of sentence,end of sentence),具体作用如下:
| 符号 | 作用 |
|---|---|
<PAD> | 补齐序列长度 |
<SOS> | 序列开始标记 |
<EOS> | 序列结束标记 |
"<SOS>", "<EOS>"比较好理解,标记开始与结束,但是这个<PAD>是干什么的?后续我们就知道了。
# 构建中文和英文词表
src_vocab = set("".join([s for s, _ in data])) # 中文按字切分
tgt_vocab = set(" ".join([t for _, t in data]).split()) # 英文按词切分
src_vocab = ["<PAD>", "<SOS>", "<EOS>"] + list(src_vocab)
tgt_vocab = ["<PAD>", "<SOS>", "<EOS>"] + list(tgt_vocab)
词表构建好后,我们就可以给每一个词建立一个索引表双向都要映射,这样,我们每一个词都能以一个数字来表示。
src2idx = {w: i for i, w in enumerate(src_vocab)}
idx2src = {i: w for i, w in enumerate(src_vocab)}
tgt2idx = {w: i for i, w in enumerate(tgt_vocab)}
idx2tgt = {i: w for i, w in enumerate(tgt_vocab)}
之后我们需要将数据集中的每一个句子转换成数字,就要借助这个索引表来转换:
# 将句子转为索引
def encode_src(text):
return [src2idx[w] for w in text] + [src2idx["<EOS>"]]
def encode_tgt(text):
words = text.split()
return [tgt2idx["<SOS>"]] + [tgt2idx[w] for w in words] + [tgt2idx["<EOS>"]]
src_seqs = [encode_src(s) for s, _ in data]
tgt_seqs = [encode_tgt(t) for _, t in data]
现在我们得到了src_seqs和tgt_seqs。这两个列表,该列表即为每个句子用索引表示的列表集合。
接着我们要进行一个操作叫做padding。因为我们每个句子的长度是不一样的,通过索引生成的序列的长度也是不一样的,但是大多数神经网络(尤其是 RNN/LSTM/Transformer 的 batch 训练)要求同一个 batch 内每个样本的输入形状一致。所以我们就需要保证每一个句子的序列长度相同,那么就需要补齐,一般采用的方法就是将所有短的序列填充成最长序列的长度,那填充什么呢?这就用到了我们前面的<PAD>填充符,该填充符是存在于词表中的,所以我们就用该词对应的索引填充每一个短的句子:
# padding
max_src_len = max(len(s) for s in src_seqs)
max_tgt_len = max(len(t) for t in tgt_seqs)
def pad(seq, max_len, pad_idx):
return seq + [pad_idx] * (max_len - len(seq))
src_seqs = [pad(s, max_src_len, src2idx["<PAD>"]) for s in src_seqs]
tgt_seqs = [pad(t, max_tgt_len, tgt2idx["<PAD>"]) for t in tgt_seqs]
之后我们再将填充好的索引序列放到torch中的tensor中:
src_tensor = torch.tensor(src_seqs)
tgt_tensor = torch.tensor(tgt_seqs)
得到:
src_tensor:
tensor([[13, 15, 2, 0],
[12, 12, 2, 0],
[ 7, 8, 15, 2],
[ 4, 9, 2, 0],
[ 3, 14, 2, 0],
[ 5, 10, 13, 2],
[13, 15, 6, 2],
[ 5, 11, 15, 2]])
tgt_tensor:
tensor([[ 1, 12, 2, 0, 0],
[ 1, 8, 5, 2, 0],
[ 1, 9, 11, 2, 0],
[ 1, 9, 10, 2, 0],
[ 1, 15, 2, 0, 0],
[ 1, 3, 7, 5, 2],
[ 1, 4, 6, 5, 2],
[ 1, 3, 14, 13, 2]])
其中我们发现目标序列中的开头都是1,结尾都是0或者2,所以1为<SOS>, 2为<EOS>, 0为<PAD>,而输入序列不需要<SOS>,因为输入序列主要工作在编码器中,在编码器中,我们的任务是将所有的输入序列压缩成一个隐藏状态向量,而目标序列是工作在解码器中的,而解码器中需要<SOS>来告诉模型序列是从这里开始的。到这里,我们只有索引序列,我们从索引序列转换为embedding向量是在模型中实现的。
encoder模块
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, batch_first=True)
def forward(self, src):
embedded = self.embedding(src) # (B, L, E)
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell # 最后的 hidden/cell 用作解码器初始状态
代码比较短,可以看到初始化需要三个参数:input_dim, emb_dim, hid_dim,
我们先来看一下后边调用该类时的代码:
encoder = Encoder(len(src_vocab), emb_dim=16, hid_dim=32)
input_dim即为src_vocab的长度,即有多少个词,emb_dim=16, hid_dim=32,这两个即为输入向量的维度和隐层的输入维度,input_dim这个参数是在nn.Embedding中用到的,nn.Embedding的输入是一个索引序列列表,输出是对应的词嵌入,作用就是将索引序列列表中的每个词的索引序列转成一个维度为emb_dim大小的序列,所以初始化的时候要传入词表的长度,即input_dim表示有多少个词,以及emb_dim表示每个词的维度是多少。其次就是nn.LSTM,要传入输入的每个token的维度以及隐层的维度,即emb_dim, hid_dim。
接着看一下forward函数,forward函数传入了src,那这个src是什么?那就得提前看看后边的代码了。
model = Seq2Seq(encoder, decoder, device).to(device)
src_tensor, tgt_tensor = src_tensor.to(device), tgt_tensor.to(device)
for epoch in range(200):
optimizer.zero_grad()
output = model(src_tensor, tgt_tensor)
因为Seq2Seq的forward函数为:
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
这里的src_tensor即为最终传到encoder中的src。
这个src_tensor即为前面输入序列的索引化序列。这个索引化序列先经过了nn.embedding,转成嵌入向量,维度转为: (B, L, E),B代表batch_size,即有多少个seq序列,L代表每个序列的长度,即每个序列有多少个token,E代表每个token转成嵌入向量的长度,这里E的大小即为emb_dim。最后
outputs, (hidden, cell) = self.rnn(embedded)
因为nn.LSTM是有两个返回,

其中outputs用来接收output,output包含全部时间步的隐藏态,
h_n和c_n是最后时刻的隐藏态和细胞态,我们只需要最后时刻的隐藏态即可,所以我们只需要返回h_n和c_n,来传递给后边的decoder。decoder模块
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim):
super().__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, batch_first=True)
self.fc = nn.Linear(hid_dim, output_dim)
def forward(self, input, hidden, cell):
input = input.unsqueeze(1) # (B, 1)
#因为decoder中LSTM每次处理一个时间步,所以需要将输入的维度从(B,)变为(B,1)
#正常的输入应该是(batch_size, seq_len,inputsize),这里是一个时间步,所以seq_len=1
embedded = self.embedding(input) # (B, 1, E)
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc(output.squeeze(1)) # (B, V) squeeze(1)去掉时间步维度
#V = vocab_size(词表大小)每一行都是对 整个词表的打分(logits),哪个词的分数高,那么就趋于预测该词
#CrossEntropyLoss 内部已经自带 softmax 所以训练时 不需要显式做 softmax
return prediction, hidden, cell
decoder = Decoder(len(tgt_vocab), emb_dim=16, hid_dim=32)
初始化还是老样子,先将索引化序列embedding一下,然后经过nn.LSTM,这里我们发现多了一个线性层,这个线性层是干啥的呢?他是由hid_dim映射到 output_dim,这个output_dim就是len(tgt_vocab),即为词表的长度。阅读下边的forward函数,我们可以发现我们每次其实是处理一个时间步的数据,实际上这个线性层干的就是,对于每一个词的评分,所以输出维度就是len(tgt_vocab)即输出词表的长度。就类似图像分类的时候,最后都会来一个线性层+softmax,类似的道理,他会对词表里的所有词,进行一个评分,评分最大的即为下一个最可能输出的词。
接着我们看forward函数,
关于这个函数:
input = input.unsqueeze(1) # (B, 1)
是在指定位置插入一个长度为 1 的维度,unsqueeze(1)即在dim=1的地方插入一个长度为1的维度(注:dim从0开始)
import torch
x = torch.tensor([1,2,3,4]) # shape (4,)
print(x.shape) # torch.Size([4])
y = x.unsqueeze(0) # 在 dim=0 插
print(y.shape) # torch.Size([1,4])
"""
[[1,2,3,4],]
"""
z = x.unsqueeze(1) # 在 dim=1 插
print(z.shape) # torch.Size([4,1])
"""
[
[1],
[2],
[3],
[4],
]
"""
我们这个input是我们人为控制输入进来的,是只包含一个时间步的数据,因为decoder中,是一次处理一个时间步的token,对应到索引序列中,即为每一列的数据 即:
tensor([[ 1, 12, 2, 0, 0],
[ 1, 8, 5, 2, 0],
[ 1, 9, 11, 2, 0],
[ 1, 9, 10, 2, 0],
[ 1, 15, 2, 0, 0],
[ 1, 3, 7, 5, 2],
[ 1, 4, 6, 5, 2],
[ 1, 3, 14, 13, 2]])
当t=0时,且batch_size=8时,取第一列,传入的数据input即为:
[1,1,1,1,1,1,1,1],那经过input.unsqueeze(1),即为:
[
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
]
为什么要这么做?
因为nn.LSTM要求传入的是:(B,L,E),即batc_size(多少个序列),每个序列的长度(每个序列有多少个token),每个token的维度,现在我们传入的为:(B,)即batch_size,在decoder中,我们是一次处理一个时间步,一个时间步只有一个token,所以第二个维度是确认了的,为1,所以我们手动给它加上,之后再进行self.embedding,转成正常的维度(B,L,E),之后我们传入nn.LSTM,这里传入LSTM时,还包含了来自encoder的hidden和cell.
之后
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc(output.squeeze(1)) # (B, V) squeeze(1)去掉时间步维度
#V = vocab_size(词表大小)每一行都是对 整个词表的打分(logits),哪个词的分数高,那么就趋于预测该词
#CrossEntropyLoss 内部已经自带 softmax 所以训练时 不需要显式做 softmax
return prediction, hidden, cell
问题又来了,这里为什么要output.squeeze(1)一下?
首先是这个函数的作用:
y = x.squeeze(dim)
dim 参数:指定要挤掉的维度
如果该维度大小是 1,就会被去掉
如果该维度大小大于 1,就不做操作
如果不写 dim:会去掉所有大小为 1 的维度
output.squeeze(1) 会把 dim=1中长度为1的维度 去掉,那这里就是将(B,1,H)转换为:(B,H),H为隐藏层维度。
为什么这么转换呢?可以从两个方面解答。
首先就是nn.Linear的输入要求,

他是需要(*,in_features),前面这个
*一般为batch_size,所以我们肯定得变为这个形式,然后,因为我们decoder中就只处理一个时间步的数据,我们前面加这个时间步,也只是为了可以输入到nn.LSTM中,所以我们现在也不需要这个维度了,所以就将这个维度去掉了。之后我们喂给线性层:
prediction = self.fc(output.squeeze(1))
这里就是从(B,H)转换为:(B,V),V为词表的大小,我们怎么理解这个含义呢?可以理解为,每一行即为每一个序列,一共V列,既可以代表为每个序列在当前时间步(当前token)对整个词表的打分,即预测下一个时间步最有可能的单词是什么。
encoder+decoder
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
# teacher_forcing_ratio:使用真实目标词作为下一个输入的概率
batch_size, tgt_len = tgt.shape #(8,5)
outputs = torch.zeros(batch_size, tgt_len, len(tgt_vocab)).to(self.device)
#初始化outputs的维度大小
hidden, cell = self.encoder(src)
input = tgt[:, 0] # 第一个输入是 <SOS> 取所有行的第一列,即为代表<SOS>的索引,这里取所有行,
#则batch_size=8,在正经数据集中训练时,应该为tgt[batch_size, 0]
for t in range(1, tgt_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[:, t] = output
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
top1 = output.argmax(1)
input = tgt[:, t] if teacher_force else top1
#top1是预测的下一个词,tgt[:, t] 是真实的下一个词
return outputs # (B, L, V) 每一个output是(B, V) 在经过所有时间步后,及得到(B, L, V)
#outputs的内容为,每个batch的每个时间步,对整个词表的打分
#L = tgt_len, V = vocab_size
encoder = Encoder(len(src_vocab), emb_dim=16, hid_dim=32)
decoder = Decoder(len(tgt_vocab), emb_dim=16, hid_dim=32)
model = Seq2Seq(encoder, decoder, device).to(device)
output = model(src_tensor, tgt_tensor)
__init__没什么好说的,直接看forward部分。输入的即为:src_tensor, tgt_tensor,为输入和输出的索引化序列。然后是teacher_forcing_ratio,这个后边再说。
接着就是将outputs初始化一下,outputs是用来放每一个时间步的输出的,因为我们每一个时间步都会输出一个当前时间步,样本对所有词的打分情况,所以我们我们用outputs来放所有时间步的输出。
然后就是将src_tensor经过encoder,得到hidden和cell。之后就是构建input,因为decoder中,每一次输入都是当前时间步的,对应到tgt_tensor即为每一个token,即为每一列,所以我们一开始输入的是<SOS>,前面说过,第一列为代表<SOS>而我们这里一共就8个数据,所以batch_size为8,
input = tgt[:, 0]
#实际上应该为:
inpu=tgt[batch_size, 0]
之后我们看下边这个循环,这个循环实际上就是处理每一个时间步的。
for t in range(1, tgt_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[:, t] = output
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
top1 = output.argmax(1)
input = tgt[:, t] if teacher_force else top1
#top1是预测的下一个词,tgt[:, t] 是真实的下一个词
从t=1开始,经过decoder,我们得到了一个维度为(batch_size,V)的数据,即为当前时间步每个样本对所有词的打分情况,我们先将这个打分情况存入outputs,outputs的大小为(batch_size, tgt_len, len(tgt_vocab)),
举个例子:
初始化为:
outputs =
[
[ [0,0,0], [0,0,0], [0,0,0], [0,0,0] ], # 第1个样本,4个时间步,每步对词表3个打分
[ [0,0,0], [0,0,0], [0,0,0], [0,0,0] ] # 第2个样本
]
假设t=1时,decoder 给出:
output = [
[0.1, 0.7, 0.2], # 第1个样本预测
[0.8, 0.1, 0.1] # 第2个样本预测
]
执行outputs[:, 1] = output之后:
outputs =
[
[ [0,0,0], [0.1,0.7,0.2], [0,0,0], [0,0,0] ],
[ [0,0,0], [0.8,0.1,0.1], [0,0,0], [0,0,0] ]
]
接下来讲一下teacher_forcing_ratio这个参数,这个参数的意义是为了是模型快速收敛,因为我们每一个时间步的输入都是来源于上一个时间步的输出(评分最高的那个词),但是如果预测错了,那么错误会累积的,所以我们以一定概率使用真实目标的token作为下一时间步的输入,
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
top1 = output.argmax(1)
input = tgt[:, t] if teacher_force else top1
#top1是预测的下一个词,tgt[:, t] 是真实的下一个词
这里讲解一下output.argmax(1),这里会取评分最高的第二维的索引,因为output是(B,V),其实正好对应了每个词的位置,我们将词转换为索引的时候,就是用的这套规则,所以取评分最高的索引,那就是取对应的词的索引。
例:
output = torch.tensor([
[0.1, 2.5, 0.3, 0.2, 0.4], # 样本1
[1.2, 0.4, 0.1, 2.0, 0.3], # 样本2
[0.3, 0.1, 0.5, 0.2, 0.6], # 样本3
])
top1 = output.argmax(1)
得到:
top1 = tensor([1, 3, 4])
分别取分数最高的那个索引,即为对应的词作为下一个时间步的输入。
当teacher_force触发时,就会取当前时间步的真实索引tgt[:, t]。
循环结束后,返回最终所有时间步的评分。
训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
encoder = Encoder(len(src_vocab), emb_dim=16, hid_dim=32)
decoder = Decoder(len(tgt_vocab), emb_dim=16, hid_dim=32)
model = Seq2Seq(encoder, decoder, device).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=tgt2idx["<PAD>"])# 忽略补齐序列
optimizer = optim.Adam(model.parameters(), lr=0.01)
src_tensor, tgt_tensor = src_tensor.to(device), tgt_tensor.to(device)
for epoch in range(200):
optimizer.zero_grad()
output = model(src_tensor, tgt_tensor)
# 忽略第一列 <SOS>
output_dim = output.shape[-1]# ouput的维度为(B, L, V)
output = output[:, 1:].reshape(-1, output_dim)
#<SOS> 只是 decoder 的起始符,不参与 loss 计算 所以不算第一列
##output[:, 1:] shape = (batch_size, tgt_len-1, vocab_size)
##.reshape(-1, output_dim) → (batch_size*(tgt_len-1), vocab_size)
#为了 把 batch 和时间步 flatten,方便 CrossEntropyLoss 一次性对齐计算
# 因为在CrossEntropyLoss中,需要 预测值和目标值的形状分别为 (N, C) 和 (N,)
#C为类别数,这里即为词表大小,N为样本数,这里即为 batch_size*(tgt_len-1),
# 并且C为对每个类别的打分 logits
#目标值是对应每个样本实际上的类别索引,CrossEntropyLoss会自动选取分数最高的类别作为预测类别,
# 与实际目标值进行对比计算损失
tgt = tgt_tensor[:, 1:].reshape(-1)
#tgt 同理 忽略 <SOS> 之后的形状变为 (batch_size*(tgt_len-1),)
loss = criterion(output, tgt)
loss.backward()# 反向传播计算梯度
optimizer.step()# 更新参数
if (epoch+1) % 10 == 0:
print(f"Epoch {epoch+1}, Loss = {loss.item():.4f}")
这里要注意的就一个点:为什么要reshape。
就是因为nn.CrossEntropyLoss函数的输入输出要求:

在CrossEntropyLoss中,需要 预测值和目标值的形状分别为 (N, C) 和 (N,)C为类别数,这里即为词表大小,N为样本数,这里即为 batch_size*(tgt_len-1),并且C为对每个类别的打分 logits,目标值是对应每个样本实际上的类别索引,CrossEntropyLoss会自动选取分数最高的类别作为预测类别,与实际目标值进行对比计算损失。我们最后的输出output的维度为(B, L, V),我们把第一列的
<SOS>丢掉之后,在.reshape(-1,V),得到的维度为:(batch_size*(tgt_len-1), vocab_size),即给他展开了。举个例子:
假设:
batch_size=2,tgt_len=3,vocab_size=5。
output为:
| batch | t=0 logits | t=1 logits | t=2 logits |
|---|---|---|---|
| 0 | [1.2,0.1,0.3,0.0,2.0] | [0.2,1.0,0.3,2.0,0.5] | [0.5,0.7,1.2,0.0,0.3] |
| 1 | [0.0,0.5,1.0,0.2,0.8] | [1.0,0.1,0.3,0.0,2.0] | [0.2,0.2,0.1,1.5,0.4] |
tgt_tensor为:
| batch | t=0 | t=1 | t=2 |
|---|---|---|---|
| 0 | 1 | 3 | 2 |
| 1 | 2 | 4 | 3 |
平铺后:
| step | logits (vocab=5) |
|---|---|
| 0 | [1.2,0.1,0.3,0.0,2.0] |
| 1 | [0.2,1.0,0.3,2.0,0.5] |
| 2 | [0.5,0.7,1.2,0.0,0.3] |
| 3 | [0.0,0.5,1.0,0.2,0.8] |
| 4 | [1.0,0.1,0.3,0.0,2.0] |
| 5 | [0.2,0.2,0.1,1.5,0.4] |
平铺后tgt_tensor为:
[1, 3, 2, 2, 4, 3]
这样就可以分别的对应上了,之后送入CrossEntropyLoss 就能一行行地对每个时间步计算损失,再求平均。之后反向传播。
完整代码实现:
import torch
import torch.nn as nn
import torch.optim as optim
# ====================
# 1. 构造数据
# ====================
data = [
("你好", "hello"),
("谢谢", "thank you"),
("早上好", "good morning"),
("晚安", "good night"),
("再见", "goodbye"),
("我爱你", "i love you"),
("你好吗", "how are you"),
("我很好", "i am fine"),
]
# 构建中文和英文词表
src_vocab = set("".join([s for s, _ in data])) # 中文按字切分
tgt_vocab = set(" ".join([t for _, t in data]).split()) # 英文按词切分
src_vocab = ["<PAD>", "<SOS>", "<EOS>"] + list(src_vocab)
tgt_vocab = ["<PAD>", "<SOS>", "<EOS>"] + list(tgt_vocab)
src2idx = {w: i for i, w in enumerate(src_vocab)}
idx2src = {i: w for i, w in enumerate(src_vocab)}
tgt2idx = {w: i for i, w in enumerate(tgt_vocab)}
idx2tgt = {i: w for i, w in enumerate(tgt_vocab)}
# 将句子转为索引
def encode_src(text):
return [src2idx[w] for w in text] + [src2idx["<EOS>"]]
def encode_tgt(text):
words = text.split()
return [tgt2idx["<SOS>"]] + [tgt2idx[w] for w in words] + [tgt2idx["<EOS>"]]
src_seqs = [encode_src(s) for s, _ in data]
tgt_seqs = [encode_tgt(t) for _, t in data]
# padding
max_src_len = max(len(s) for s in src_seqs)
max_tgt_len = max(len(t) for t in tgt_seqs)
def pad(seq, max_len, pad_idx):
return seq + [pad_idx] * (max_len - len(seq))
src_seqs = [pad(s, max_src_len, src2idx["<PAD>"]) for s in src_seqs]
tgt_seqs = [pad(t, max_tgt_len, tgt2idx["<PAD>"]) for t in tgt_seqs]
src_tensor = torch.tensor(src_seqs)
tgt_tensor = torch.tensor(tgt_seqs)
# print(src_tensor)
# print(tgt_tensor)
"""
src_tensor:
tensor([[13, 15, 2, 0],
[12, 12, 2, 0],
[ 7, 8, 15, 2],
[ 4, 9, 2, 0],
[ 3, 14, 2, 0],
[ 5, 10, 13, 2],
[13, 15, 6, 2],
[ 5, 11, 15, 2]])
tgt_tensor:
tensor([[ 1, 12, 2, 0, 0],
[ 1, 8, 5, 2, 0],
[ 1, 9, 11, 2, 0],
[ 1, 9, 10, 2, 0],
[ 1, 15, 2, 0, 0],
[ 1, 3, 7, 5, 2],
[ 1, 4, 6, 5, 2],
[ 1, 3, 14, 13, 2]])
"""
#1为<SOS>, 2为<EOS>, 0为<PAD>
# ====================
# 2. 构建模型
# ====================
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, batch_first=True)
def forward(self, src):
embedded = self.embedding(src) # (B, L, E)
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell # 最后的 hidden/cell 用作解码器初始状态
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim):
super().__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, batch_first=True)
self.fc = nn.Linear(hid_dim, output_dim)
def forward(self, input, hidden, cell):
input = input.unsqueeze(1) # (B, 1)
#因为decoder中LSTM每次处理一个时间步,所以需要将输入的维度从(B,)变为(B,1)
#正常的输入应该是(batch_size, seq_len,inputsize),这里是一个时间步,所以seq_len=1
embedded = self.embedding(input) # (B, 1, E)
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc(output.squeeze(1)) # (B, V) squeeze(1)去掉时间步维度
#V = vocab_size(词表大小)每一行都是对 整个词表的打分(logits),哪个词的分数高,那么就趋于预测该词
#CrossEntropyLoss 内部已经自带 softmax 所以训练时 不需要显式做 softmax
return prediction, hidden, cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
# teacher_forcing_ratio:使用真实目标词作为下一个输入的概率
batch_size, tgt_len = tgt.shape #(8,5)
outputs = torch.zeros(batch_size, tgt_len, len(tgt_vocab)).to(self.device)
#初始化outputs的维度大小
hidden, cell = self.encoder(src)
input = tgt[:, 0] # 第一个输入是 <SOS> 取所有行的第一列,即为代表<SOS>的索引,这里取所有行,
#则batch_size=8,在正经数据集中训练时,应该为tgt[batch_size, 0]
for t in range(1, tgt_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[:, t] = output
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
top1 = output.argmax(1)
print(output.argmax(1))
input = tgt[:, t] if teacher_force else top1
#top1是预测的下一个词,tgt[:, t] 是真实的下一个词
return outputs # (B, L, V) 每一个output是(B, V) 在经过所有时间步后,及得到(B, L, V)
#outputs的内容为,每个batch的每个时间步,对整个词表的打分
#L = tgt_len, V = vocab_size
# ====================
# 3. 训练
# ====================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
encoder = Encoder(len(src_vocab), emb_dim=16, hid_dim=32)
decoder = Decoder(len(tgt_vocab), emb_dim=16, hid_dim=32)
model = Seq2Seq(encoder, decoder, device).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=tgt2idx["<PAD>"])
optimizer = optim.Adam(model.parameters(), lr=0.01)
src_tensor, tgt_tensor = src_tensor.to(device), tgt_tensor.to(device)
for epoch in range(200):
optimizer.zero_grad()
output = model(src_tensor, tgt_tensor)
# 忽略第一列 <SOS>
output_dim = output.shape[-1]# ouput的维度为(B, L, V)
output = output[:, 1:].reshape(-1, output_dim)
#<SOS> 只是 decoder 的起始符,不参与 loss 计算 所以不算第一列
##output[:, 1:] shape = (batch_size, tgt_len-1, vocab_size)
##.reshape(-1, output_dim) → (batch_size*(tgt_len-1), vocab_size)
#为了 把 batch 和时间步 flatten,方便 CrossEntropyLoss 一次性对齐计算
# 因为在CrossEntropyLoss中,需要 预测值和目标值的形状分别为 (N, C) 和 (N,)
#C为类别数,这里即为词表大小,N为样本数,这里即为 batch_size*(tgt_len-1),
# 并且C为对每个类别的打分 logits
#目标值是对应每个样本实际上的类别索引,CrossEntropyLoss会自动选取分数最高的类别作为预测类别,
# 与实际目标值进行对比计算损失
tgt = tgt_tensor[:, 1:].reshape(-1)
#tgt 同理 忽略 <SOS> 之后的形状变为 (batch_size*(tgt_len-1),)
loss = criterion(output, tgt)
loss.backward()# 反向传播计算梯度
optimizer.step()# 更新参数
if (epoch+1) % 10 == 0:
print(f"Epoch {epoch+1}, Loss = {loss.item():.4f}")
# ====================
# 4. 测试翻译
# ====================
def translate(sentence):
model.eval()
with torch.no_grad():
src = torch.tensor([pad(encode_src(sentence), max_src_len, src2idx["<PAD>"])]).to(device)
hidden, cell = model.encoder(src)
input = torch.tensor([tgt2idx["<SOS>"]]).to(device)
result = []
for _ in range(max_tgt_len):
output, hidden, cell = model.decoder(input, hidden, cell)
top1 = output.argmax(1)
word = idx2tgt[top1.item()]
if word == "<EOS>":
break
result.append(word)
input = top1
return " ".join(result)
for src, _ in data:
print(f"{src} -> {translate(src)}")