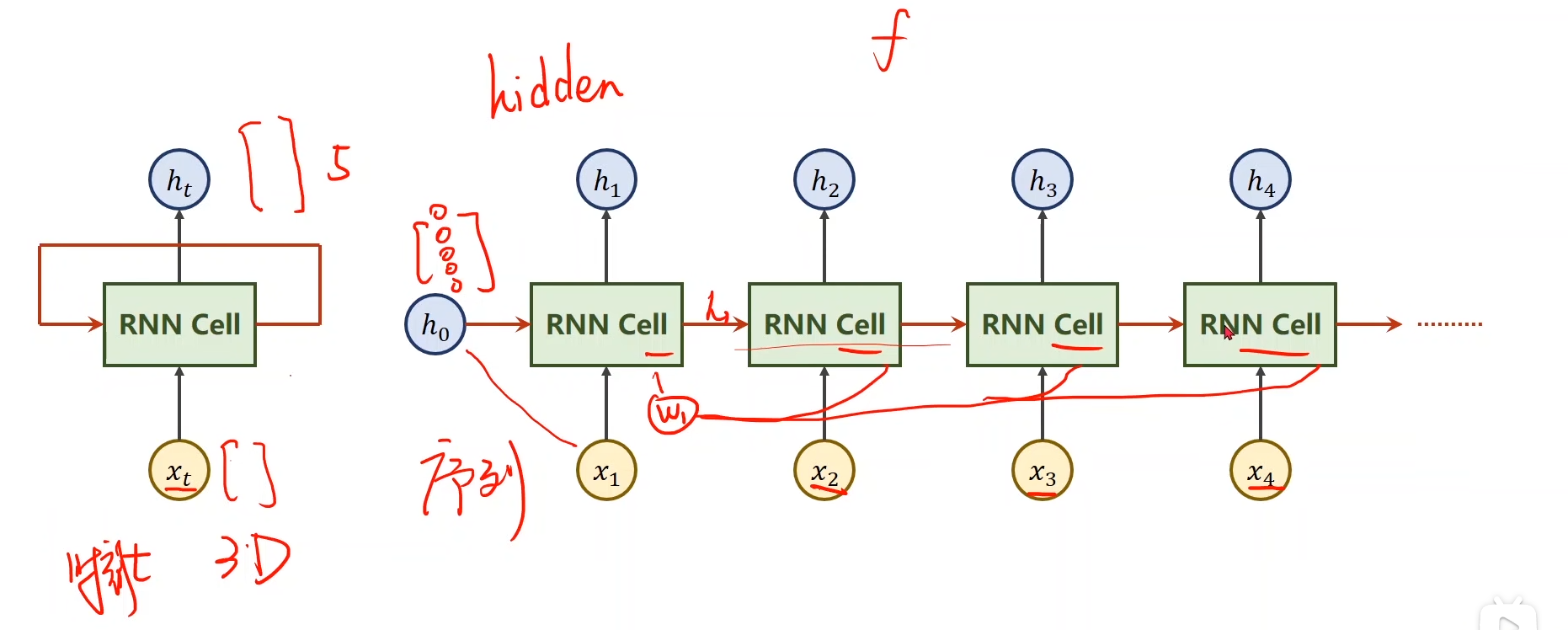
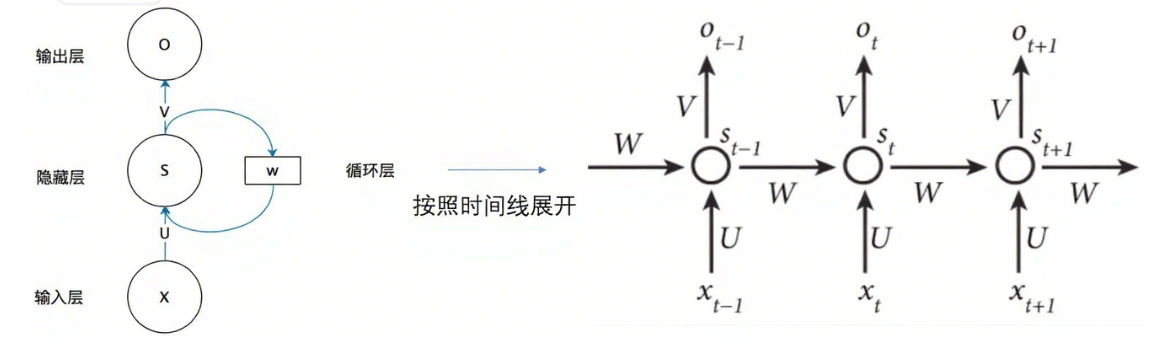
1.前言
在2022年11月30日,ChatGPT横空出世。ChatGPT和GPT看起来都是GPT,为什么ChatGPT可以“Chat”? 首先从官方寻找答案:

可以看到ChatGPT和InstructGPT的训练方法一摸一样,只不过InstructGPT是基于GPT3的,ChatGPT是基于GPT3.5的。而有关GPT‑3.5相较于GPT3的区别,除了自然语言上的优化,最主要的就是多了代码生成能力
所以想要知道ChatGPT是如何具有chat能力,那就去看InstrcutGPT的原理即可
论文地址:https://arxiv.org/pdf/2203.02155
2.动机
论文的题目为:让语言模型遵从来自人类反馈的指令。 这也是为什么将他叫做InstructGPT。我们知道,在GPT3中,openai主要的卖点是few-shot、1-shot甚至zero-shot。即推崇让预训练好的模型不经过下游任务样本的专门训练,只需要给几个prompt,就直接完成下游NLP任务。但是在instruct GPT中作者又说了这么做的缺陷:

模型经常会捏造一些事实(实际上2025年的大模型还是会捏造事实😂),生成一些有偏见或者一些toxic(有毒的)的文字。或者是单纯的不遵循用户的指令。
为什么?

因为这些预训练模型在训练的时候的任务都是:next token prediction. 这个任务的目标函数是达不到“遵循用户的指令”的目标的。openai把这种现象称为:"未对齐的"
3.方法
上边就已经把这篇文章的工作动机都说完了,那么如何解决这个现象?作者使用的方法为:
We focus on fine-tuning approaches to aligning language models. Specifically, we use reinforcement learning from human feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020)
没错就是RLHF,也是我写这篇博客的目的。
RLHF全称为:"reinforcement learning from human feedback":来自人类反馈的强化学习。
但是instruct GPT中的RLHF有三个阶段,而RLHF只包含了后边两个阶段。在人类反馈的强化学习之前,还要先进行一步:supervised fine-tuning(SFT)。在我的理解中,这里的SFT就是大模型微调中的指令微调,二者没有本质区别。
所以instruct GPT用到的技术就是:指令微调+RLHF:
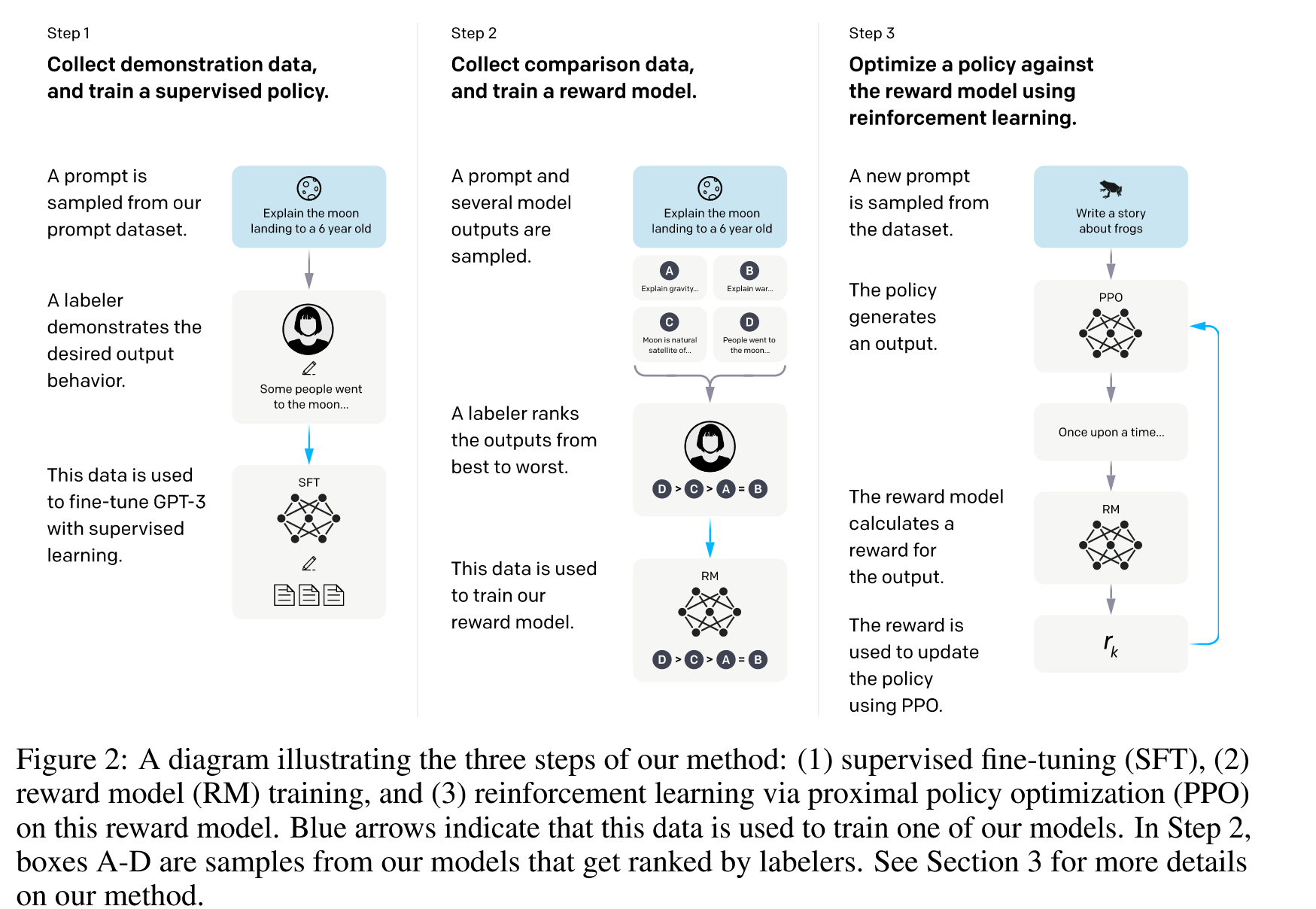
这张图很清晰。接下来我们分别来看三个阶段。
3.1 supervised fine-tuning (SFT)
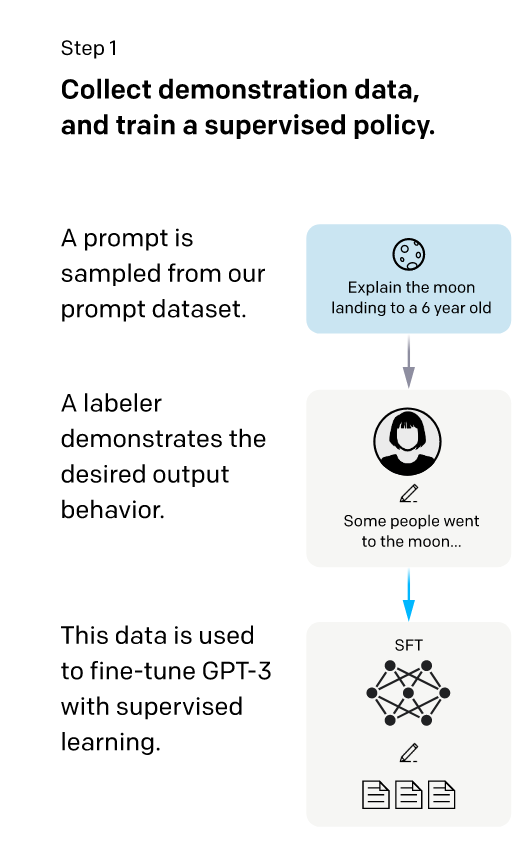
第一阶段就是让数据标注员标来自prompt dataset的数据,关于图中这个这个prompt数据集:可以看论文的3.2节:
Our prompt dataset consists primarily of text prompts submitted to the OpenAI API, specifically those using an earlier version of the InstructGPT models (trained via supervised learning on a subset of our demonstration data) on the Playground interface.4 Customers using the Playground were informed that their data could be used to train further models via a recurring notification any time InstructGPT models were used. In this paper we do not use data from customers using the API in production. We heuristically deduplicate prompts by checking for prompts that share a long common prefix, and we limit the number of prompts to 200 per user ID. We also create our train, validation, and test splits based on user ID, so that the validation and test sets contain no data from users whose data is in the training set. To avoid the models learning potentially sensitive customer details, we filter all prompts in the training split for personally identifiable information (PII).
这些prompt主要来自openai API,这个API主要是最开始版本的InstructGPT models,这个最开始版本的模型主要在有限的数据集上进行训练,它的性能肯定就有限,之后公开出去供用户调用,然后openai再将用户问他的一些prompt收集起来作为后续模型迭代的数据(这里也强调了用户是知情的,并且也将一些私人信息删除了)。
而第一阶段就是让数据标注员标来自prompt dataset的一部分数据,而标记的细节就是让数据标注员回答每个prompt分别作为每条数据的label。
论文中也提到了最开始版本的模型是如何训练的:
To train the very first InstructGPT models, we asked labelers to write prompts themselves. This is because we needed an initial source of instruction-like prompts to bootstrap the process, and these kinds of prompts weren’t often submitted to the regular GPT-3 models on the API. We asked labelers to write three kinds of prompts:
Plain: We simply ask the labelers to come up with an arbitrary task, while ensuring the tasks had sufficient diversity. Few-shot: We ask the labelers to come up with an instruction, and multiple query/response pairs for that instruction. User-based: We had a number of use-cases stated in waitlist applications to the OpenAI API. We asked labelers to come up with prompts corresponding to these use cases.
就是让数据标注员自己写一些prompt以及回答作为最初的指令数据集。并且还不能瞎写,是有要求的:主要三个要求:第一个是确保任务是多样性的,第二个就是指令数据集的格式:描述+多个query/response pairs,第三个是要指令基于用户的,要符合来自OPENAI API的的用户prompt。利用这些初始数据集,在GPT3上进行训练,就得到了最原始的InstructGPT models,之后再利用API中的数据进行再次标注+训练。就得到了SFT模型
经过以上步骤,我们就训练出了一个最初始的SFT模型,即经过指令微调的模型。
事实上,如果数据标注员足够勤奋(😏),能够把所有数据都标好的话,其实Instruct GPT只需要基于这些数据集训练就够了。但用户提交的prompt太多了! 根本标不完,所以需要发明一个自动标注的方法,这个方法还必须可靠,符合人类偏好。 所以RLHF诞生了,也就是第二和第三阶段。
3.2 Reward modeling (RM).
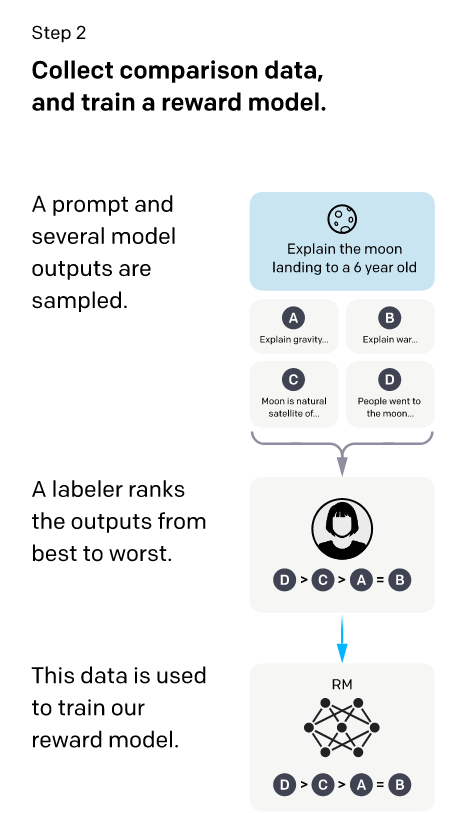
上边说了,RLHF就是一个基于人类偏好的自动标注方法。因为prompt很多时候并不像简单的分类或者回归问题,他是需要输出一段话的,所以光用人类标注就太累了,而大模型本身擅长输出一段话,但是这个质量不能保证,所以对于每一个prompt,让上边初始训好的SFT模型模型生成K个回答,再由人类对这些回答进行排序或者打分。这样就会省事一点。 但是!光这样还是太费labeler了(😂),能不能再训一个模型,让这个模型自动对SFT生成的K个回答进行自动打分排序? 这就是我们第二阶段的Reward modeling,它的作用就是对SFT生成的多个回答进行排序,并且这个排序逻辑是基于人类反馈的。那训练这个RM也需要数据集,这个数据集就得人类标注了。
对于一个prompt,先让上边的SFT模型输出K个回答,与prompt拼起来作为K个数据,即:prompt+answer为一个数据。之后让人类对每个回答进行排序,排出一个高低,这里也可以理解为对每个回答进行打分,但是得给他们排个高低。这些标好的数据集,就作为我们的Reward modeling的训练数据集。
Reward modeling的结构

Reward modeling就是将上边训好的最原始的SFT模型的unembedding layer(也就是最后一个线性层) 去掉。 RM模型的目的是输出一个分数,来为每个数据打分,而SFT模型输出是在词表上的概率分布。所以删去了最后一个线性层。
关于这里的细节,作者说详细看附录C。附录C中是这么说的:
All model architectures use the GPT-3 architecture (Brown et al., 2020). For the reward models and value functions, the unembedding layer of the original model is replaced with a projection layer to output a scalar value.
GPT经过decoder-block输出的维度为:(Batch_size,seq_len,hidden_states),而最后我们需要输出的是对于每一个seq的标量打分,即:(Batch_size,1)。那么这个转换的过程是怎么进行的?附录中只说了用projection layer代替unembedding layer但这也是做不到直接删减两个维度的。那中间这个维度变换怎么处理的?
先说结论:(Batch_size,seq_len,hidden_states)取最后一个token的hidden_states。因为这最后时刻的hidden_states就融合了前面所有时刻token的信息。 这样维度就变成了(Batch_size,hidden_states)之后经过一个线性层,转变成(batche_size,1)。
以下为我寻找证据的过程:
首先锁定权威资料Huggingface:他有一个库名字叫trl,意为Transformer Reinforcement Learning
这里边有一个脚本文件名字为reward_modeling.py。从名字也能看出来他是干什么的
Github地址为:
https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py

这个model就是我们的RM了,而他这里model用的AutoModelForSequenceClassification来加载,这里这个num_labels=1的作用就是将最后的输出从(Batch_size,seq_len,hidden_states)转变为(batche_size,1)。怎么转变的呢?可以从官方文档中各个model的介绍看到。因为GPT3没有开源,而GPT3是基于GPT2的。所以可以看一下GPT2。
https://huggingface.co/docs/transformers/v4.53.3/model_doc/gpt2
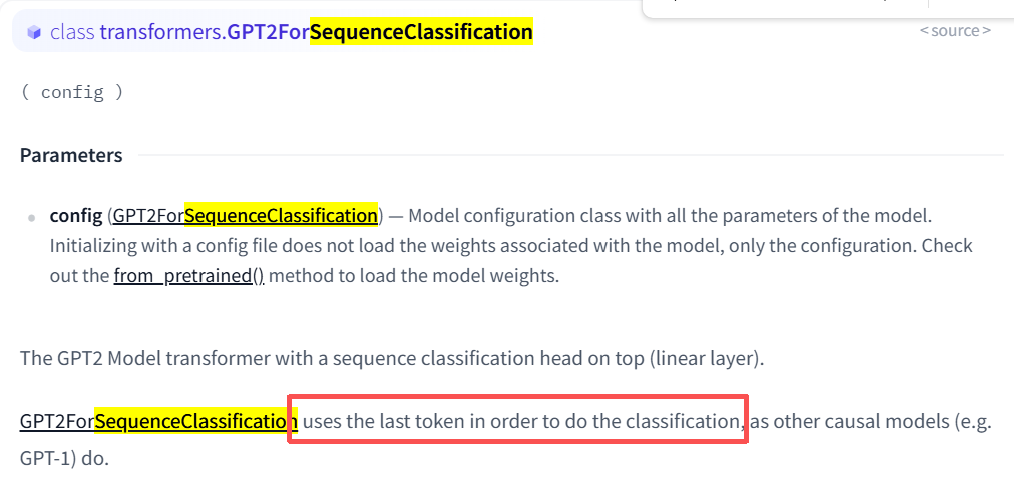
可以看到是将最后一个token拿出来。和我们上边说的一样。我也同样看了类似GPT结构的因果解码器模型LLaMA、Qwen等,他们都是一样的操作。
Reward modeling的损失函数
前面我们说了RM的目的是给回答好坏程度进行排序,openai采用的方式是Pairwise(成对比较)的方法。因为RM会输出分数,代表对(prompt,answer)的好坏评价。所以要干的就是对于任意两对数据,RM都可以将他们区分出好坏,也就是尽量使两个回答的输出分数差距变大。 所以每个回答对作为一个数据集。那对于一个prompt,如果有K个回答,那么就会产生个数据。
即原文中所说:
the RM is trained on a dataset of comparisons between two model outputs on the same input. They use a cross-entropy loss, with the comparisons as labels—the difference in rewards represents the log odds that one response will be preferred to the other by a human labeler.
而数据集的分布是将每一个prompt对应的所有回答作为一个batch。具体原因有两个:一个是如果将数据打乱了,会容易过拟合。而第二个就是将每一个prompt对应的回答作为一个batch每次就只需要一次前向传播。原文如下:

为什么会过拟合?

简单来说就是:
如果把同一个 prompt 下的所有 pairwise comparisons 当成独立的数据点,那么每个回答的梯度会被重复更新很多次 (K−1 次),导致模型在一个 epoch 内就完全记住(过拟合)这些回答。
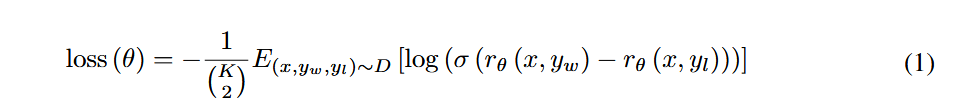

首先看最核心的部分,即
其中 指的是RM的输出,可以看作模型认为回答y对prompt x的质量分数,而表示winner,指更好的回答,表示loser,即更坏的回答。指的是sigmoid函数,值越大,越接近1 ,否则接近0 (二分类)。外边加一个log也是常规操作了。所以我们的目的就是让更好的回答的分数减去更坏的回答分数 这个值更大。是包含每一个pairwise的数据集
然后前面多了两个看不太懂的数学符号:
首先是第一个:,为什么要除以它?的意义就是
对于一个prompt,他有K个回答,所以会产生个pairwise对。为了让每一个prompt的贡献大小一样,所以要平均一下。这一步是在Prompt内部取平均。为的是让每一个pairwise对不会因为他的K多,就产生更多的损失
而是期望的意思,这一步是在整体数据集上取平均。将损失平均到整个数据集上,将损失平均到每一条数据集上。
之后再加一个负号,那么最小化即可
3.3 Reinforcement learning (RL)
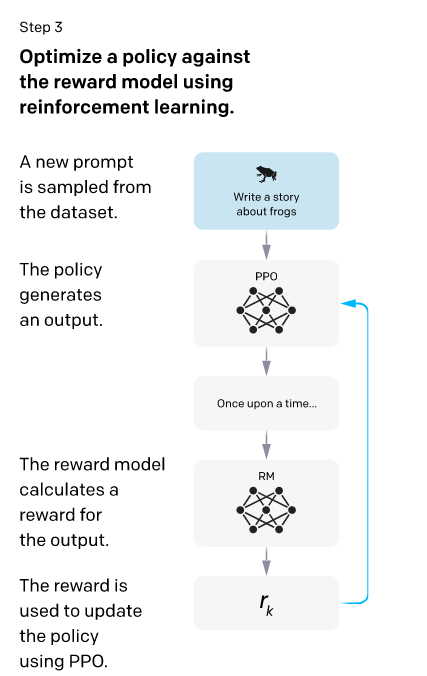
这里就是强化学习的部分了。openai采用的是一个叫做PPO-ptx的策略,是在PPO策略上的改进。因为也没学过强化学习。我们大概知道就是需要目标函数上最梯度下降就行了。我们直接来看目标函数:

看到这么一大坨公式确实是被吓了一跳。我们逐步来看。我们的目的是最大化,那肯定就要最最大化。就是我们RM输出的目标分数。前面我们知道。RM模型就是对回答进行打分的。所以他肯定越大越好,越大代表着输出我们人类更喜欢的回答。
那第二项这么一大坨是什么?下边的注释说:指的是RL policy,这个policy也是一个强化学习术语,我们就可以理解为当前我们要优化的一个模型,他的初始是和(即我们最初的SFT模型)是一样的。我们从一开始构建的那个prompt数据集中拿出来一个数据,然后丢到中,这样会产生一个Y,这个Y会放到RM中产生一个值来反过来对RL模型进行更新,而更新之后,我们的模型就发生变化了,然后再次拿一个新的prompt输入进来,再产生Y进行新的更新。 理论上来说其实最大化就可以了,但是这样我们产生的新RL模型可能会偏离我们最初的SFT模型会较远。
所以就有了第二项:
这项叫做KL散度,我们希望他比较小,是接近于0的小,而不是小到负无穷,如果小到负无穷的话,那么意味着接近0,那这样的话就不会产生新的y了,那也不满足最大化这个函数了。所以我们希望接近1,这样新的RL模型和原始的SFT模型是相差不大的,最理想的情况就是他俩完全一样,此时第二项的KL散度即为0。
对于第三项,第三项就是原始GPT3训练时的损失函数,这里意思是不要把在原始数据训好的模型丢掉。多偏向于原始数据一些,他和第二项KL散度的区别就是重点不同,KL散度是告诉不能偏离 SFT 太远。主要是输出风格。第三项是主要是数据层面,不要忘记GPT3的原始数据。(个人理解)
总结
整个 instruct GPT核心部分就是上边提到的三个阶段,即指令微调、RLHF。这也是学习大模型比较重要的知识,而论文中还涉及到其他各种细节,包括实验结果,还有数据机构建、数据标注员的选择,还是挺有意思的。但有一点就是英语还是得练😭。
有时间再写写GPT1、GPT2、GPT3的小结(埋坑大王就是我)