前言
本篇文章是读完《Neural Machine Translation by Jointly Learning to Align and Translate》(Bahdanau et al., 2014)之后所写的一个关于注意力机制的小结。
它是最早提出注意力机制的论文
论文地址:https://arxiv.org/abs/1409.0473
论文摘要
首先看看本篇论文的摘要部分

前面主要是介绍了什么是神经机器翻译,也就是基于神经网络的翻译模型,这个概念是相对于传统机器翻译的。然后又说了现在存在的神经机器翻译都是基于encoder-decoder架构的。作者用一句话就概括了这个架构在干什么,即:源语句(我们要翻译的句子)通过encoder,生成一个固定长度的向量,然后将向量放入decoder产生翻译。之后又说他们推测这个固定向量就是阻止传统encoder-decoder架构表现更好的瓶颈。接下来作者提出了可以说是本篇论文的idea:
and propose to extend this by allowing a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word, without having to form these parts as a hard segment explicitly.
"通过扩展传统encoder-decoder架构,让模型能够自动的(以软搜索的方式)在源语句中找到与预测词相关的部分,并且不需要将源语句显示的划分成硬性的片段" 这里这个软搜索就是注意力机制了。
后边就是介绍这个新模型的性能了,作者将这个模型与当时最先经的基于短语的翻译系统在英语翻译成法语任务上进行了对比。
除此之外作者还对模型进行了定性分析,这个软对其(软搜索)方式,与我们人类进行翻译时的直觉很像。这个定性分析就是将这种软搜索定义成"attention"的原因,因为这个表现就和我们人类的直觉很像。
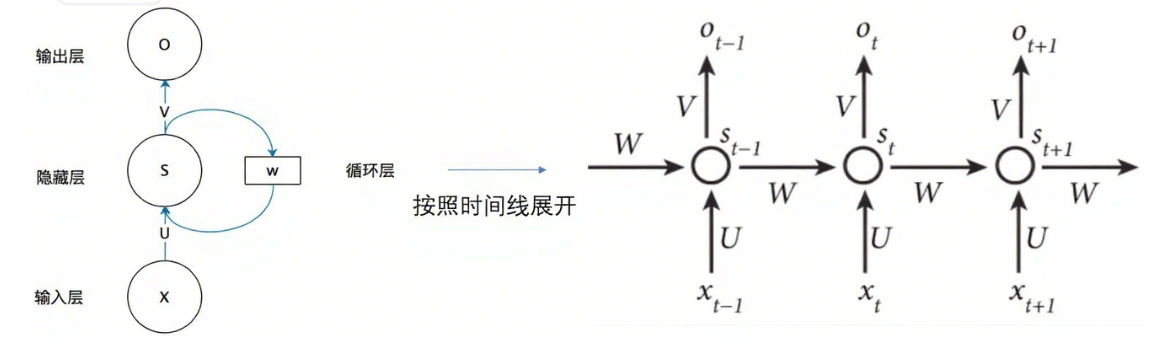
传统encoder-decoder架构会在encoder部分将输入序列压缩成一个向量之后传入decoder部分,encoder和decoder之间只通过一个隐状态来传递信息,这样很容易造成信息丢失,在处理较长的文章时,这种架构的表现不够理想。并且也不符合常理,
那么基于注意力机制的encoder-decoder架构就出现了。
传统encoder-decoder架构的不足
摘要完了之后就是第一部分的INTRODUCTION章节,主要就是讲了传统encoder-decoder架构的不足。我挑了一些核心有用的部分去读。
首先是传统encoder-decoder架构干了什么:
An encoder neural network reads and encodes a source sentence into a fixed-length vector. A decoder then outputs a translation from the encoded vector. The whole encoder–decoder system, which consists of the encoder and the decoder for a language pair,is jointly trained to maximize the probability of a correct translation given a source sentence.
将源语句读入encoder,产生一个固定长度的向量,然后decoder借助这个固定向量产生翻译结果。整个encoder-decoder架构,包含encoder和decoder以及语言对(即源语句和目标语句)会进行联合训练,目标就是在给定源语句的情况下,最大化翻译正确的概率。
接下来就是这种架构的不足了。
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus. Cho et al. (2014b) showed that indeed the performance of a basic encoder–decoder deteriorates rapidly as the length of an input sentence increases.
一个潜在的不足就是这个网络需要去将源语句中所有需要的信息压缩到一个固定长度的向量,这可能让神经网络很难处理长句子,尤其在训练语料库中比较长的一些句子,Cho等人就展示了传统的encoder–decoder架构在输入语句变长时,模型表现会急剧恶化。
OK说的很明白了。
注意力机制
我么们已经知道了,注意力机制,就是摘要中提到的"软搜索"
论文在第一章后边又笼统的,但是比摘要详细的介绍了一下自己提出了什么novel idea,然后第二章的 BACKGROUND就是介绍了一下已有的基础encoder-decoder架构,然后第三章开始详细介绍这篇paper的idea,也就是我们要学的注意力机制。我们直接读第三章。
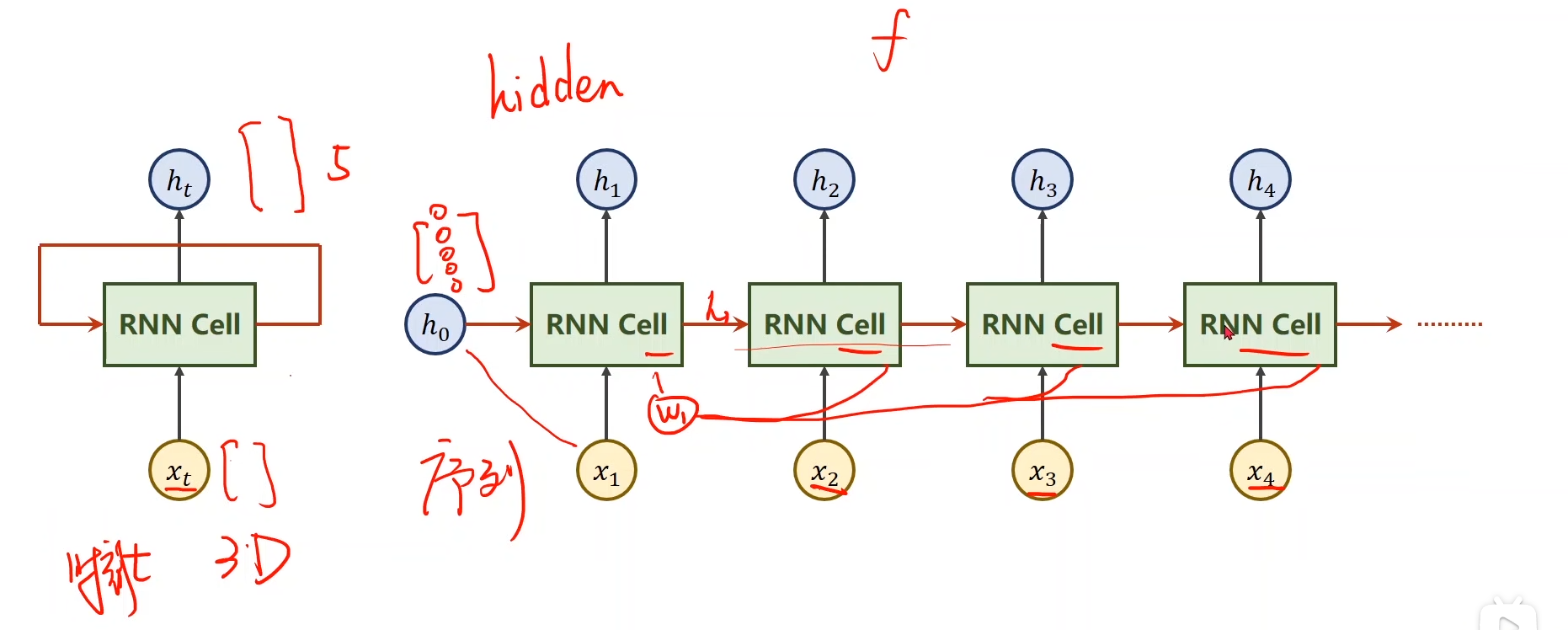
decoder部分介绍
In this section, we propose a novel architecture for neural machine translation. The new architecture consists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searching through a source sentence during decoding a translation (Sec. 3.1)
原文中是先介绍的decoder,后介绍的encoder,可能是decoder是他的核心创新点,所以先介绍decoder吧,那我们也按照论文顺序先看decoder模块。

首先是列了一下条件概率,其中图片中提到公式二是前文中介绍RNN时提到的:
在这个新架构中,此公式的每一项为:
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt,
这里的其实就是用来输出对词表的概率分布的,一般为MLP+softmax
其中
where si is an RNN hidden state for time i
这里的就是nn.LSTM或者nn.RNN等网络。
It should be noted that unlike the existing encoder–decoder approach (see Eq. (2)), here the probability is conditioned on a distinct context vector ci for each target word yi.
这句话就是说,每一个的生成,都是基于一个不同的上下文向量的,而传统encoder-decoder架构是基于一个由encoder生成的固定长度的向量。而这个,就是由注意力机制产生的。
The context vector ci depends on a sequence of annotations(h1,.....,hTx) to which an encoder maps the input sentence. Each annotation hi contains information about the whole input sequence with a strong focus on the parts surrounding the i-th word of the input sequence. We explain in detail how the annotations are computed in the next section.
这个上下文向量是基于一个注释,这个注释是来映射输入序列的,每一个注释都包含整个输入序列的信息,并且对于输入序列的第个单词的周围部分有很强的关注度(注意力),我们会在下一节解释这个注释的计算方法。
这个注释其实就是隐藏层,至于为什么作者要把他称为"annotations",他会在下一节解释。
紧接着贴出了的计算公式:
where:
is an alignment model which scores how well the inputs around position j and the output at position match. The score is based on the RNN hidden state (just before emitting yi, Eq. (4)) and the j-th annotation of the input sentence.
这个就是一个对齐模型,用于给输入序列中第j个位置和输出序列中第i个位置进行打分,这个打分用来评判这两个位置有多匹配(其实就是相似度,这个分数就是相似度分数,也可以是注意力分数),这个分数是基于RNN中的hidden state 和输入序列中第j个位置中的
其实这个就是我们的注意力机制了,他的作用就是将decoder中第个位置的隐藏层,和前面encoder中所有位置的隐藏层进行计算,计算这个相似度(即注意力分数)。
我们知道,其实alignment score = attention score但是为什么论文中叫做alignment model?因为在传统机器翻译中,通常都是采用"硬"对齐的方法,比如翻译 I love you -> 我爱你。I对齐我,love对齐爱,you对齐你。而作者前面摘要就写了这里是一个软搜索的模式,其实就是软对齐,就是强调这个模型的作用就是学习源序列和目标序列的对齐关系的。但后边就叫做注意力机制了,因为它更像我们人类的注意力。
在decoder中,得到当前隐藏层对输入序列中所有隐藏层即每个词语的之后,我们接着:
其实就是softmax了一下。
其实这两步做的就是,在检测当前输出词的时候,计算一下与输入序列中每一个词的相似度,然后再softmax一下,就得到了对输入序列的每个词的注意力权重大小。
之后
再加权求和,即可得到我们要的上下文向量了。
综上所述,这几步操作用我们人类思维去思考,做的事情就是,在预测当前要输出新的词()的时候,我先返回去看看整个输入序列,看看当前已经考虑过的词()和整个输入序列中的每个词()的相似度,考虑考虑哪个词是和当前已经考虑过的词更相关(这一步就是加权求和)。
注意力分数计算方法
前面介绍了decoder架构的大体架构,并且提出了一个注意力分数,就是计算两个向量的相似度,但是我们怎么计算两个向量的相似度呢?也就是说:,这个到底是什么呢?
在该篇论文中:
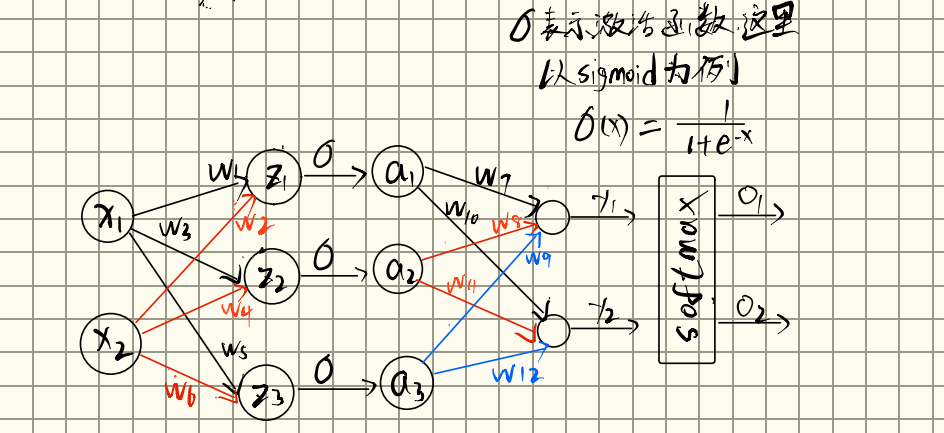
We parametrize the alignment model as a feedforward neural network which is jointly trained with all the other components of the proposed system. Instead, the alignment model directly computes a soft alignment, which allows the gradient of the cost function to be backpropagated through.This gradient can be used to train the alignment model as well as the whole translation model jointly.
作者采用了一个FNN,也就是MLP,一个简单的线性变换,并且,这个注意力计算函数也可以和整个系统一块训练,也就是说这个注意力函数也是会和encoder、decoder一块训练,前向传播到损失函数计算损失,然后进行反向传播,更新参数。这个注意力函数的方式后来被称为
Bahdanau 注意力,也叫加性注意力。
这个注意力的具体形式在论文的后边:
其中,和是可训练的参数矩阵,是可训练的向量,这个向量的作用是:会得到一个向量,这个向量与点积得到一个标量。即注意力分数。
实际上,计算两个向量相似度的方法还有其他的。前面我们学过,计算两个向量相似度最直接的方法就是两个向量做点积:
两个向量做点积的几何意义就是是将一个向量投影到另一个向量上,得到在另一个向量方向上的投影分量。
点积越大,那么这两个向量就越相似。
所以就有另一种计算注意力分数的方法:点积注意力。
随之延申出来的还有就是:缩放点积注意力。所谓缩放点积,就是在点积注意力的基础上又缩放了一下,避免梯度过大,Transformer中就是采用的这种注意力方式。后续也会讲到为什么要缩放一下子。
这种注意力分数的计算方法就是计算量小,并且这里没有权重需要更新。

这也是全文中唯一有attention的部分,注意力机制也是由此得来的,最为核心的一句:
Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed length vector
从直觉上来说,我们在decoder中实现了一个注意力机制,decoder决定着源语句将他的注意力放在哪,通过让decoder拥有注意力机制,我们使之前那种让encoder尝试将含源语句所有信息放入一个固定长度的向量这种方式得到了缓解。
encoder部分介绍。
标题是:
ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
作者采用了一个双向RNN。
we would like the annotation of each word to summarize not only the preceding words, but also the following words.
作者希望隐藏态不仅可以概括前面的单词,并且可以概括后边的单词,所以作者encoder采用了 bidirectional RNN,这个网络模型在语音识别方面比较成功。
然后接下来就是介绍了一下双向RNN的结构

首先将正向的隐藏态,和反向的隐藏层进行拼接得到
通过这种方式,能够包含词前面的和后面的信息总结。
由于RNN更擅长处理近期inputs,所以会关注周围的单词。然后这个就会被解码器以及注意力模型用来计算上下文向量。
encoder部分就这么简单。
总结
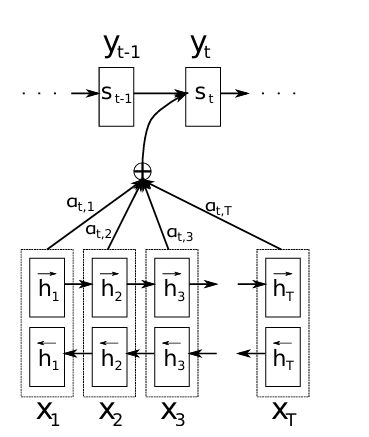
这次我们再看这个模型架构图就非常简单明确了。
通过Attention机制的引入,我们打破了只能利用encoder最终单一固定长度向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。并且这个注意力机制,还有一个好处,就是可以实现对齐———这也是论文中为什么总把注意力模型叫做alignments model.因为他真的实现了软对齐。原论文除了用BLEU score来衡量模型性能外,还对模型进行了定性分析( QUALITATIVE ANALYSIS)。

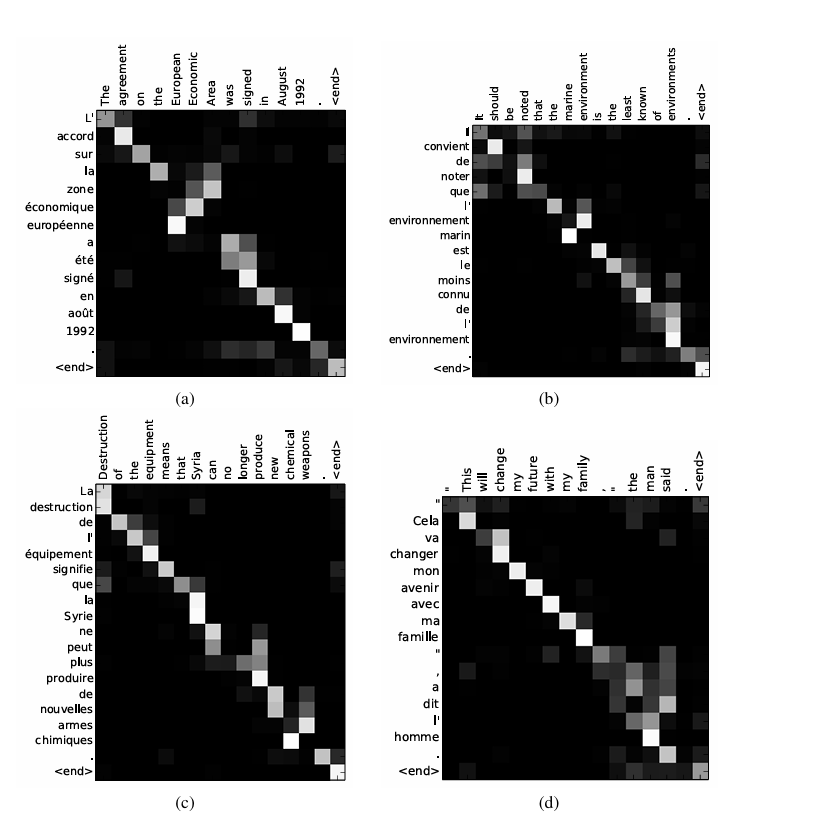
以上是在对齐方面进行的定性分析,作者主要可视化分析了,也就是注意力权重矩阵,来了解模型在生成目标词的时候,关注了源输入语句中的哪些单词。并且相对于硬对齐,该模型的允许一个词可以对齐不止一个单词,也就是说,一个单词可以关注源输入的不同单词,而不是一一对应,这些都使模型在翻译任务中表现更好了。具体例子作者也都有分析。
除此之外,作者还分析了该模型在长句子上的表现。

也都是明显表现比传统encoder-decoder架构好的。