LoRA小结 前言:PEFT的诞生 传统的预训练-下游任务微调的范式,是对预训练模型所有参数进行微调,即全量微调。之前基于Bert、GPT1的下游微调任务都是这么干的。因为当时的预训练模型参数量比较少,所以速度并没有那么慢。…
|
623
|
|
2674 字
|
11 分钟
GPT3与ChatGPT有什么不同?——RLHF技术小结 1.前言 在2022年11月30日,ChatGPT横空出世。ChatGPT和GPT看起来都是GPT,为什么ChatGPT可以“Chat”? 首先从官方寻找答案: 可…
|
745
|
|
4173 字
|
18 分钟
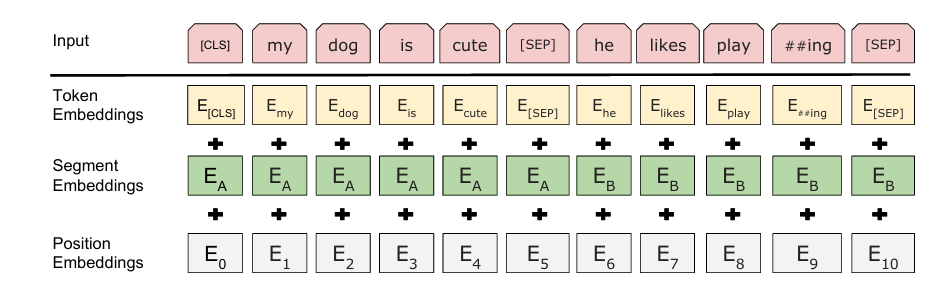
Bert源码解读(HuggingFace Transformers源码) BertMoedel的架构组成: 在HuggingFace中,对应Bert模型的主要就是BertMoedel这个类: from transformers import BertModel HF源码对BertMoedel的封装也是一…
|
929
|
|
5193 字
|
25 分钟
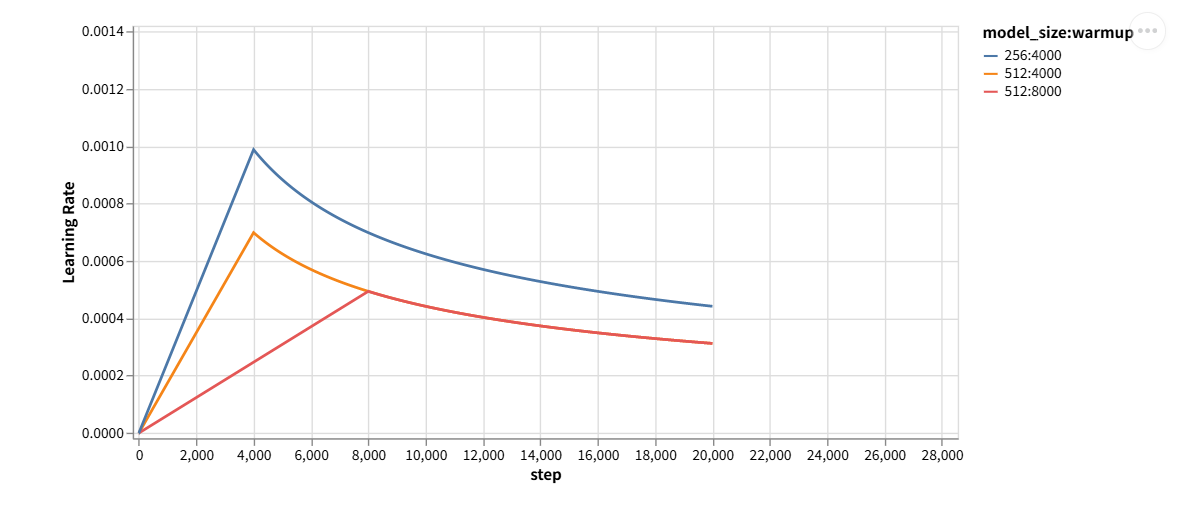
The Annotated Transformer学习笔记(Transformer的pytorch实现)(下) 前言 上篇已经模型架构的代码都学习了,本章学习一下如何训练。 Batches and Masking 文章中的很多模块功能都是定义一个类,首先是batch和mask…
|
972
|
|
3498 字
|
16 分钟
The Annotated Transformer学习笔记(Transformer的pytorch实现)(上) 前言 本文章为《The Annotated Transformer》的学习笔记。文章名为:带有注释版的Transformer,实际上就是用代码实现了一下《attention is all your need》中的各个章节模块。原文地址:https://nlp.…
|
1,145
|
|
5493 字
|
26 分钟
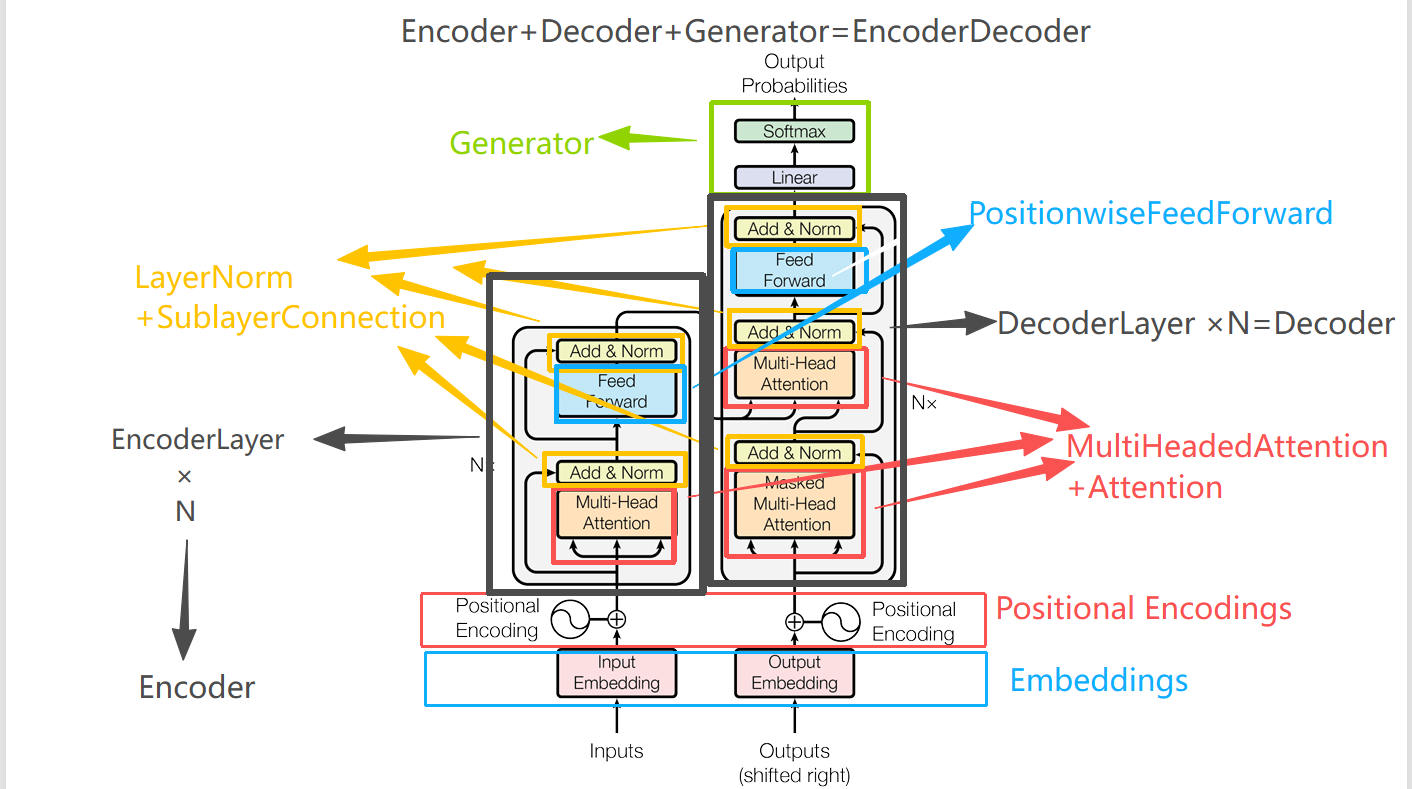
Transformer小结 前言 终于!!前面学了那么多,终于轮到主角登场了:大名鼎鼎的Transformer。理所当然的,就要去读一下原论文:《attention is all your need》 论文地址:https://arxiv.org/pdf/1706.03762 论文摘要介…
|
1,062
|
|
9308 字
|
39 分钟
基于encoder-decoder架构的注意力机制 前言 本篇文章是读完《Neural Machine Translation by Jointly Learning to Align and Translate》(Bahdanau et al., 2014)之后…
|
1,086
|
|
3921 字
|
16 分钟
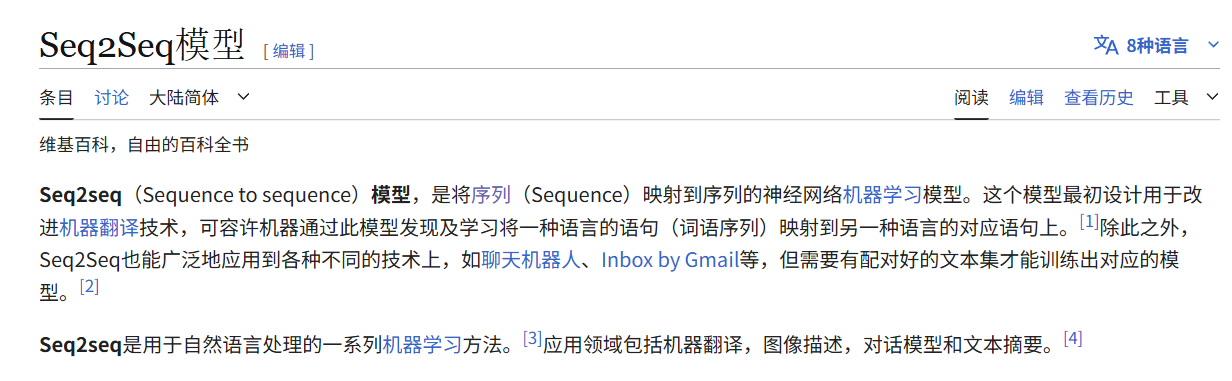
Seq2Seq模型与encoder-decoder架构(附代码实现一个小小demo) 前言 学习解码器与编码器架构以及注意力机制是为了后边更好的学习Transformer架构。本文为作者学习encoder-decoder架构的学习笔记。 encoder-decoder架构 诞生背景 &…
|
1,205
|
|
4313 字
|
22 分钟
LSTM小结 LSTM所解决的问题(LSTM解决了RNN的什么缺陷?) LSTM的全名是:Long Short-term Memory(LSTM),即长 短时记忆神经网络。我们知道LSTM是一种特殊的RNN,那他相较于RNN改…
|
1,008
|
|
3815 字
|
15 分钟
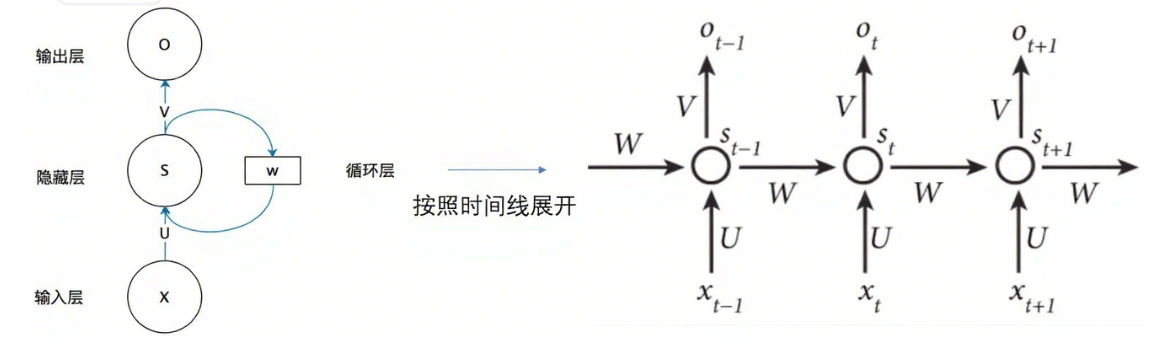
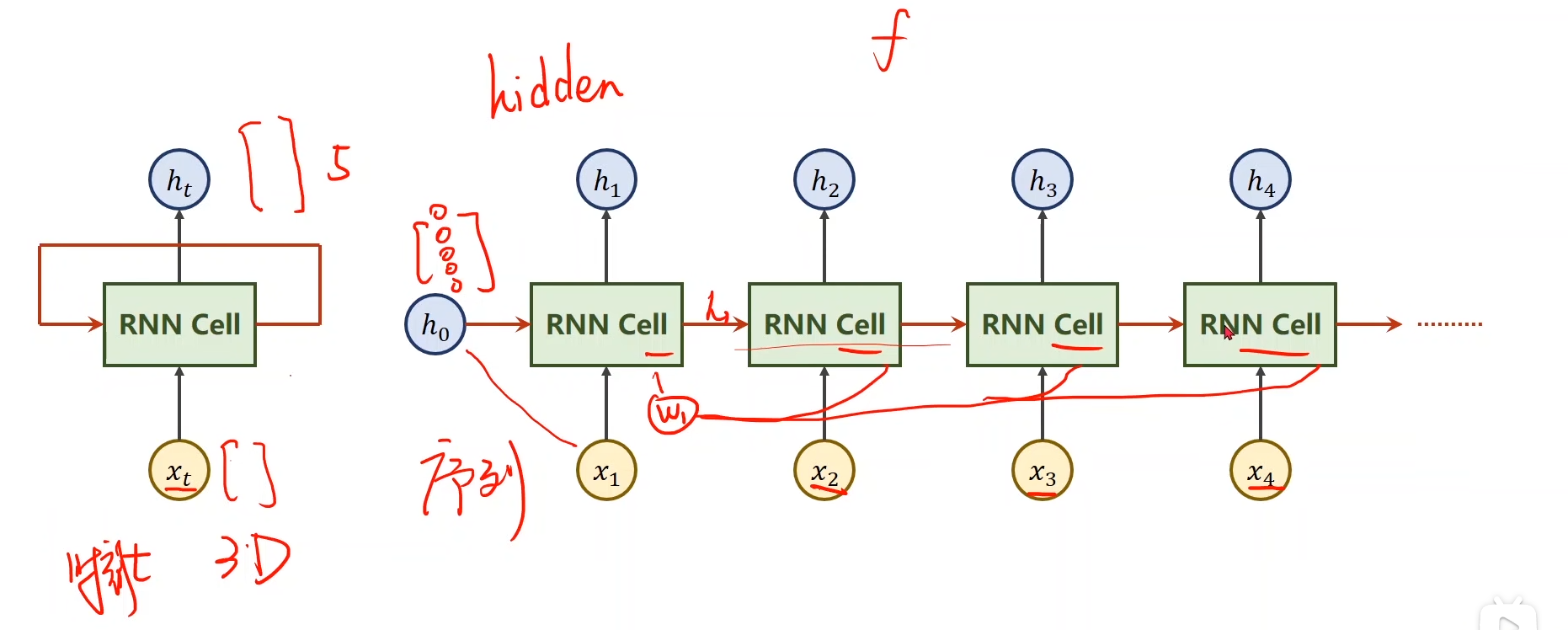
循环神经网络小结 RNN所解决的问题 RNN是专门处理具有序列关系的输入数据而诞生的网络,它能挖掘数据中的时序信息以及语义信息 序列关系数据 什么是具有序列关系的数据呢? 主要就是符…
|
1,610
|
|
3997 字
|
16 分钟